io_uring - new code, new bugs, and a new exploit technique
For the past few weeks, I have been working on conducting N-day analysis and bug hunting in the io_uring subsystem of the Linux kernel with the guidance of my mentors, Billy and Ramdhan.
In this article, I will briefly discuss the io_uring subsystem, as well as my approach to discovering and developing a new kernel exploit technique during my N-day analysis of CVE-2021-41073. I will also discuss two bugs I found while analyzing a new io_uring feature.
What is io_uring?
The io_uring subsystem was created by Jens Axboe to improve the performance of I/O operations (file read/write, socket send/receive). Traditionally, such I/O operations that require interaction with the kernel occur via system calls (syscalls), which incur significant overhead due to the need for context switches from user to kernel mode and back. This can have a significant impact on programs that perform a large number of such I/O operations, such as web servers. It is currently planned to be integrated into NGINX Unit. io_uring consists of both a kernel subsystem (mostly located in fs/io_uring.c) and a userland library (liburing).
Instead of using syscalls for every request, io_uring enables communication between user and kernel mode via two ring buffers, which are shared between kernel and userland: the submission queue (SQ) and completion queue (CQ). As their names suggest, userland programs place I/O requests on the SQ, where they are dequeued and processed by the kernel. Completed requests are placed on the CQ, allowing the userland program to retrieve the results of the operation.
SQ and CQ operations are asynchronous: adding a request to the SQ will never block, unless the queue is full, in which case an error is returned.
io_uring can be configured to either continuously check (poll) the SQ for new requests, or a syscall (io_uring_enter) can be used to inform the kernel that new requests are present. The kernel can then either process the request in the current thread, or delegate it to other kernel worker threads.
io_uring is one of the fastest growing subsystems in the Linux kernel, with support for new kinds of I/O operations continuously being added. fs/io_uring.c is one of the largest files in the fs directory, with over 13,000 lines and 300,000 bytes (as of kernel v5.19-rc3).
With such a large and active codebase, it is no surprise that bugs such as CVE-2021-20226 and CVE-2021-3491 (found by my mentor, Billy 🙂) are continually being found in this subsystem.
Provided buffers
When synchronous I/O is performed, memory space to store results is required almost immediately. However, in asynchronous I/O, requests may not be processed for quite some time. Thus, allocating a buffer for each request consumes an unnecessarily large amount of memory. It is more efficient to allocate a pool of buffers and hand it over to io_uring to select which buffer it wants to use for a certain request. The ID of the buffer selected is returned to the userland application. This is known as legacy provided buffers, or simply provided buffers.
Unfortunately, until recently (kernel version 5.18-rc1), provided buffers were single use, and the application had to provide (or reregister) new buffers once the original buffers were used up. Very recently (mid May 2022, kernel version 5.19-rc1), ring mapped supplied buffers landed in io_uring. Provided buffers can now be tracked in a ring queue, with the first buffer in the queue being reused after the last one is used. While both are ring buffers, this mechanism is separate from the submission queue or completion queue.
The first kind of provided buffers will be relevant to the first part of the post, while the second (ring provided buffers) will be discussed in the second section.
CVE-2021-41073
CVE-2021-41073 is an incorrect free in io_uring that was discovered by Valentina Palmiotti. The bug occurs in loop_rw_iter when provided buffers are used.
static ssize_t loop_rw_iter(int rw, struct io_kiocb *req, struct iov_iter *iter)
{
...
while (iov_iter_count(iter)) {
struct iovec iovec;
ssize_t nr;
...
if (rw == READ) {
nr = file->f_op->read(file, iovec.iov_base,
iovec.iov_len, io_kiocb_ppos(kiocb));
} else {
// write to file
}
...
ret += nr;
if (nr != iovec.iov_len)
break;
req->rw.len -= nr;
req->rw.addr += nr; // bug here!
iov_iter_advance(iter, nr);
}
return ret;
}
If provided buffers are used, req->rw.addr is a kernel pointer (to an io_buffer object that manages provided buffers), not a userland pointer. Due to the incorrect increment of this pointer, the io_buffer that is supposed to be freed is not, rather the object after it is freed instead.
static unsigned int io_put_kbuf(struct io_kiocb *req, struct io_buffer *kbuf)
{
unsigned int cflags;
cflags = kbuf->bid << IORING_CQE_BUFFER_SHIFT;
cflags |= IORING_CQE_F_BUFFER;
req->flags &= ~REQ_F_BUFFER_SELECTED;
kfree(kbuf); // req->rw.addr is freed here
return cflags;
}
static inline unsigned int io_put_rw_kbuf(struct io_kiocb *req)
{
struct io_buffer *kbuf;
kbuf = (struct io_buffer *) (unsigned long) req->rw.addr;
return io_put_kbuf(req, kbuf);
}
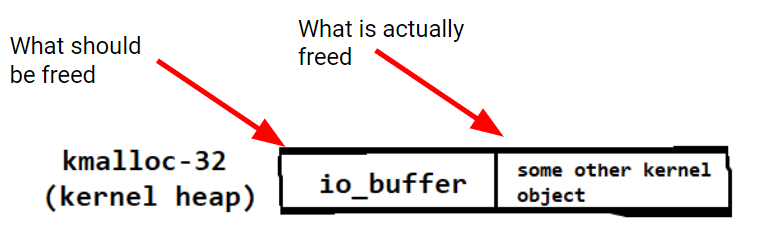
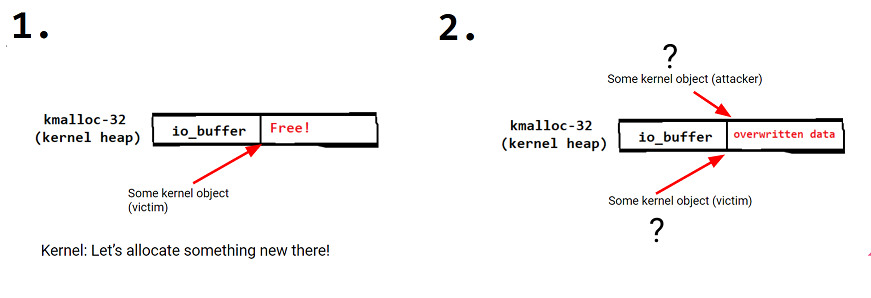
How can we exploit this incorrect free? One typical technique is to manipulate the kernel into allocating another object into the memory that was incorrectly freed. Now two kernel objects occupy the same memory, resulting in use-after-free like overwriting of memory.
Choosing a suitable kernel object
But what kernel objects should we use? Kernel memory is allocated in groups of similarly sized objects known as kmalloc caches. Each cache consists of pages which are divided into many objects of a certain size. The io_buffer is allocated to kmalloc-32, as it has a size of 32 bytes, although objects of between 16 and 32 bytes can be allocated there as well.
Much research (here and here) has been conducted on what kernel objects can be allocated into different kmalloc caches, and their value to an attacker seeking to achieve privilege escalation. For example, shm_file_data, an object allocated into kmalloc-32, can be used to leak both kernel heap and text section addresses.
However, objects that can be manipulated to be allocated into any kmalloc cache, a technique known as universal heap spray, are far and few between. Perhaps the most popular and well known is msg_msg, whose next pointer, when overwritten, allows an attacker to write to arbitrary locations in memory. Unfortunately, msg_msg objects can only be allocated into kmalloc-64 and above. A different object must be used for kmalloc-32.
In her original writeup, Valentina uses the sk_filter, which contains a pointer to an extended Berkeley Packet Filter (eBPF) program. By overwriting this pointer to an attacker controlled program, local privilege escalation can be achieved. However, this technique requires another subsystem (eBPF), another kernel object (the attacker’s eBPF program), as well as another leak (the address of attacker’s eBPF program). Additionally, eBPF is disabled by default in Ubuntu 21.10. There must be other structs for exploiting kmalloc-32.
Searching for kernel structs
I used pahole to obtain the sizes of all the structs in the linux kernel:
pahole --sizes vmlinux > all_structs.txt
Then I used a simple python script to filter the list of structs down to those with size 16-32 bytes. After extracting the definitions of each struct of interest from the kernel code, I used regex to identify structs containing a few interesting features:
- Function pointers
- Pointers to structs containing
opin their names (possibly pointers to function pointer structs) list_headstructs: containsnextandprevpointers that can be manipulated
Out of all the resultant structs, I found the simple_xattr struct to be particularly interesting, as I had been using setxattr for other parts of the exploit and knew that xattrs are likely to be controllable from userspace.
Checking the size of the struct with pahole, it is indeed 32 bytes, and contains a list_head struct:
struct simple_xattr {
struct list_head list; /* 0 16 */
char * name; /* 16 8 */
size_t size; /* 24 8 */
char value[]; /* 32 0 */
/* size: 32, cachelines: 1, members: 4 */
/* last cacheline: 32 bytes */
};
struct list_head {
struct list_head *next, *prev;
};
With some more research, I found that simple_xattr is used to store extended attributes (xattrs) for in-memory filesystems (such as tmpfs). simple_xattr objects for a certain file are stored in a linked list via the list_head pointers.
simple_xattr objects are allocated in simple_xattr_alloc when an xattr is set on tmpfs. As the value of the xattr is stored in this object, an attacker controlled amount of memory is allocated. This allows simple_xattr to be allocated into kmalloc caches from kmalloc-32 and up.
Unfortunately for an attacker, simple_xattr objects are not modified when an xattr is edited. Instead, the old simple_xattr is unlinked and a new object is allocated and added to the linked list. Thus, causing out-of-bounds/arbitrary write via overwriting the size or next pointer directly is not feasible.
Finally, the man page for tmpfs states that
The tmpfs filesystem supports extended attributes (see xattr(7)), but user extended attributes are not permitted.
This is slightly problematic, as non-privileged users cannot typically set xattrs in the other namespaces (security and trusted). However, this can be overcome by using a user namespace. In such a namespace, users can set xattrs in the security namespace, thus enabling unprivileged allocation of simple_xattr.
Unlinking attack
While an attacker cannot directly manipulate the next pointers for arbitrary write, the next and prev pointers can be used to execute an unlinking attack, resulting in a more limited arbitrary write when an xattr is removed.
Here’s the relevant code from __list_del:
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev; // 1
WRITE_ONCE(prev->next, next); // 2
}
Since we have total control over the prev and next pointers, the next pointer can be set to an address of interest, such as modprobe_path. The value of prev will be written to next in line 1.
Unfortunately, next is written to prev in line 2. This means that prev must be a valid pointer as well. This poses a significant restriction on the values that we can write to next. However, we can take advantage of the physmap to provide valid prev values.
The physmap is a region of kernel virtual memory where physical memory pages are mapped contiguously. For example, if a machine has 4GiB (2^32 bytes) of memory, 32 bits (4 bytes) are required to address each byte of physical memory available in the system. Assuming the physmap starts at 0xffffffff00000000, any address from 0xffffffff00000000 to 0xffffffffffffffff will be valid as every value (from 0x00000000-0xffffffff) of the lower 4 bytes are required to address memory.
Therefore, assuming the system has at least 4GiB of memory, an attacker can choose any value for the lower 4 bytes of prev, as long as the upper 4 bytes correspond to a physmap address.
As we are targeting modprobe_path, we will use 0xffffxxxx2f706d74 as the value of prev. If next is modprobe_path+1, modprobe_path will be overwritten to /tmp/xxxxprobe , where xxxx is the upper 4 bytes of prev. This is an attacker controlled path and can be triggered to achieve userspace code execution as the root user.
Summary of simple_xattr exploit technique
By triggering the allocation of simple_xattr into kmalloc caches from kmalloc-32 and up, and leveraging an unlinking attack, an attacker can escalate an overflow or incorrect free in the kernel heap to a limited arbitrary write. Although an attacker can only write 4 controlled bytes and 4 uncontrolled bytes, this is sufficient for Linux kernel LPE.
This technique also presents an advantage over other similar techniques such as the use of the msg_msg struct due to the lack of any metadata located before the list_head pointers. This technique requires an attacker to leak a pointer to somewhere in the physmap. However, many structures, including shm_file_data include pointers to both the text section and the physmap, so this is unlikely to be a major problem. It should also be noted that the chosen physmap address must be writable and any contents located there will be overwritten.
The entire exploit code can be found on our github repo.
Demo
It’s Demo Time.
io_uring bug hunting
After N-day analysis, I moved on to look at recent commits related to io_uring and hunt for any bugs introduced in them. This commit caught my attention as it introduced a fairly large number of changes, including a new mechanism for buffer selection, ring mapped provided buffers. This mechanism has been described in previous sections, so I will not explain it here.
The commit add io_ring_buffer_select, a function to select a buffer from the ring of provided buffers. Here’s a short snippet:
head &= bl->mask;
if (head < IO_BUFFER_LIST_BUF_PER_PAGE) {
buf = &br->bufs[head];
} else {
int off = head & (IO_BUFFER_LIST_BUF_PER_PAGE - 1);
int index = head / IO_BUFFER_LIST_BUF_PER_PAGE - 1;
buf = page_address(bl->buf_pages[index]);
buf += off;
}
The head variable is used to index the br->bufs array, which contains pointers to the provided buffers. Before array access, head is set to head & bl->mask, which ensures that it wraps around, rather than exceeding the bounds of the array.
The math in the else block seems somewhat interesting. As the number of buffers can be very large, it might not be possible to fit all the structs containing pointers to provided buffers io_uring_buf in a single page. Thus, pages allocated to store io_uring_buf objects are stored in bl->buf_pages. br->bufs points to the first page.
On most machines, which have 4KiB (2^12 byte) pages, IO_BUFFER_LIST_BUF_PER_PAGE is defined to be 256. Thus offset is set to head & 255, equivalent to head % 256, which makes sense. But why is index = head / 256 - 1? If head is 256, index would be 0, which means buf would point to the first page, which are occupied by buffers 0-255. This could cause two requests to use the same buffer, resulting in corruption of any data present in that buffer. This bug was fixed before I could report it.
Next, I decided to look at where head is incremented. It appears that head is not incremented in io_ring_buffer_select for most cases. Instead, it is incremented in __io_puts_kbuf which appears to be called only when the request is completed.
What if many requests were submitted at once? Would they all get assigned the same buffer as head is only incremented when the request completes? I decided to test it out:
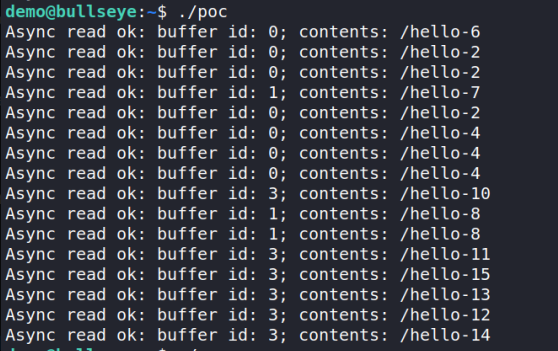
When 16 requests are submitted concurrently, 7 requests are allocated buffer 0, resulting in corrupted reads. This is a pretty clear race condition. As the head is not correctly incremented, the number of requests can exceed the number of available buffers. Thus, when these requests complete and increment head, head may exceed the number of buffers available. However, as head & bl->mask ensures head does not exceed the length of the array, no out-of-bounds bug occurs.
Since I could not determine any security impact from this bug, I decided to report it on the project’s GitHub page. The project’s maintainers were very helpful in validating the bug and pushed a fix to the kernel within 24 hours.
Unfortunately, I still do not completely understand how the fix works, and it seems the bug is a lot more complicated than I had expected.
Conclusion
As I had no prior experience with the Linux kernel, this internship was a completely new learning experience for me. I saw how the concepts I had picked up from modules on operating systems in school, such as memory management and paging, can be applied to the real world. Bug hunting has allowed me to reinforce and practice code review and exploitation techniques, such as use-after-free that can be applied to other programs. Through N-day analysis, I learnt how to write bug reports that concisely conveyed the vulnerability and exploit to ensure that all parties knew what the bug was and how to fix it. Finally, I would like to thank my mentors, Billy and Ramdhan, for their guidance and invaluable feedback throughout my internship. It’s been an amazing experience working and interacting with the employees and interns at STAR Labs, and I look forward to coming back again in the future!