At the beginning of this month, GitLab released a security patch for versions 14->15. Interestingly in the advisory, there was a mention of a post-auth RCE bug with CVSS 9.9.
 The bug exists in GitLab’s
The bug exists in GitLab’s Project Imports feature, which was found by @vakzz. Incidentally, when I rummaged in the author’s h1 profile. I discovered that four months ago, he also found a bug in the import project feature:
Initially, I thought it was tempting after seeing the bounty, so I started learning Rails and debugged this bug! (who would have thought that 30k wouldn’t be so easy ( ° ͜ʖ ͡°) )
Note that the article may be longer than usual. You can read it at leisure but if you just want the PoC, you can skip to the end to watch the video!
ENVIRONMENT SETUP & DEBUGGING
This part is also relatively cumbersome and complex, requiring patience from the position of Re-searcher! Initially, I consulted a friend’s post at Sun* to setup the environment. But after running it, it was quite slow and very unreliable, so I decided to install it myself!
My environment uses a virtual machine running Ubuntu Desktop 18.04. The first is to set up GitLab’s GDK suite first:
apt update
apt install make git -y
curl "https://gitlab.com/gitlab-org/gitlab-development-kit/-/raw/main/support/install" | bash
Wait for 15-30 minutes, and we will complete the setup of GDK. Now we can check out the vulnerable version of GitLab:
cd gitlab-development-kit/gitlab/
git checkout v15.1.0-ee
After checkout, edit the following files:
config/gitlab.yml, find the gitlab host config line and change it to the ip of the virtual machine so you can browse from the outside
gitlab:
## Web server settings (note: host is the FQDN, do not include http://)
host: 192.168.139.137
port: 3000
https: false
Find the lines with the key webpack and set enabled to false:
webpack:
dev_server:
enabled: false
After editing, go to the GitLab/ folder and type the following command to compile the server’s resources:
rake gitlab:assets:compile
config/puma.rb, find the line declaringworkersand comment again:
# workers 2
When you have finished editing the config files, type the following commands to start the related services:
gdk stop
gdk start webpack rails-background-jobs sshd praefect praefect-gitaly-0 redis postgresql
On the IDE side, I use RubyMine (a product of Jetbrains).
Using RubyMine, we can browse and open the gitlab folder. The IDE will automatically detect and install the relevant components. Add debug config by opening Run > Edit Configurations
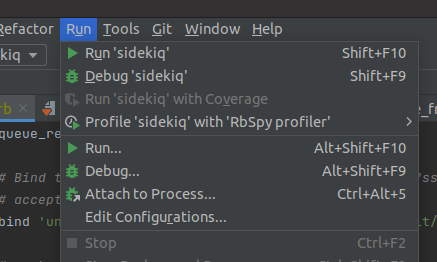
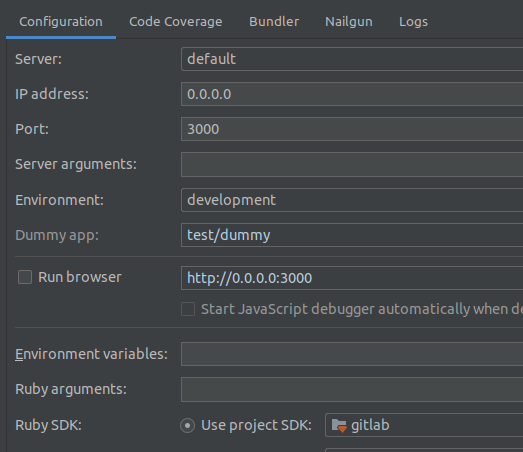
Add in the Rails config as shown below:
Then add in the sidekiq config:
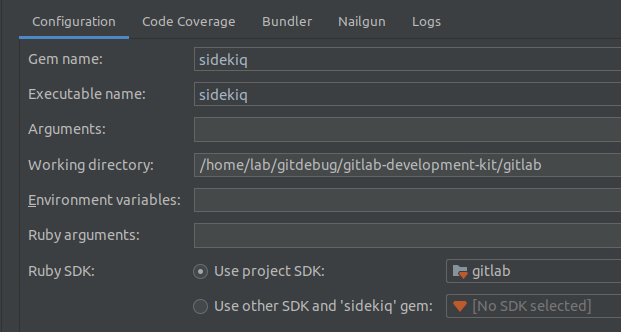
In the case of using the source code clone from GitLab’s repo, the configs for debugging are already available.
From there, it’s good to start debugging, although the sidekiq worker might not run stablely. Currently, I still do not know why sometimes it missed the job.
CVE-2022-2185 ANALYSIS
I rely on the earlier bug reported by @vakzz to analyze this bug. Although the relationship between both the bugs are barely significant in that only the entrypoint is the same and all other techniques are different, I would recommend that you read it first here wherein you will find certain techniques can be related to the old one as well.
Related information
The fixed versions were 15.1.1, 14.10.5. I choose the v15.1.1 to start the hunt
While reading the commits on gitlab-v15.1.1, it’s lucky for me that there are not many commits, yet I found a remarkable commit below:
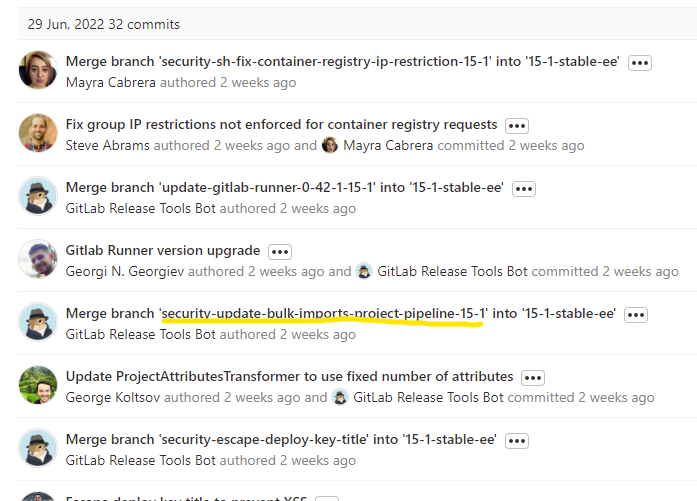
Commit 5d58c705 has an interesting name and sound relating to this bug
security-update-bulk-imports-project-pipeline-15 -1
Some remarkable changes in this commit:
At lib/gitlab/import_export/decompressed_archive_size_validator.rb
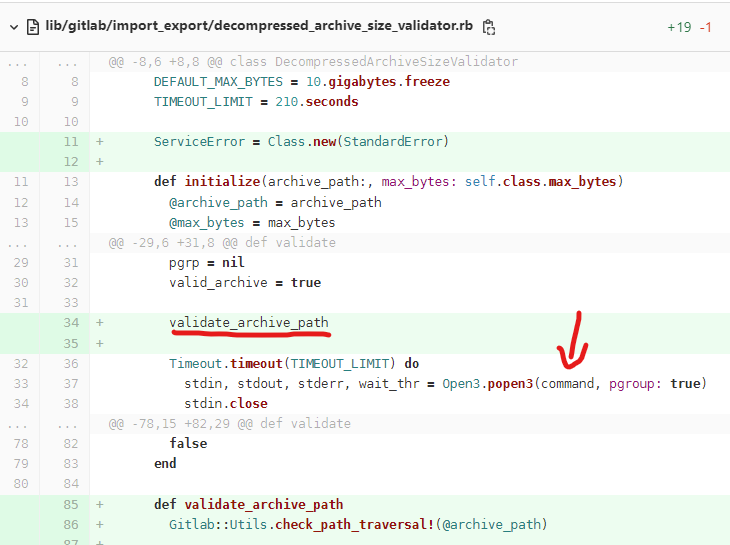
The validate_archive_path method checks cases where @archive_path is Symlink, not String and not File.
def validate_archive_path
Gitlab::Utils.check_path_traversal!(@archive_path)
raise(ServiceError, 'Archive path is not a string') unless @archive_path.is_a?(String)
raise(ServiceError, 'Archive path is a symlink') if File.lstat(@archive_path).symlink?
raise(ServiceError, 'Archive path is not a file') unless File.file?(@archive_path)
end
After calling validate_archive_path, this method will continue to call Open3.popen3(command, pgroup: true) to run the command. The command declaration is as follows:
def command
"gzip -dc #{@archive_path} | wc -c"
end
This method directly appends the string @archive_path to the command gzip -dc, so I guess the command injection bug occurs at this place!
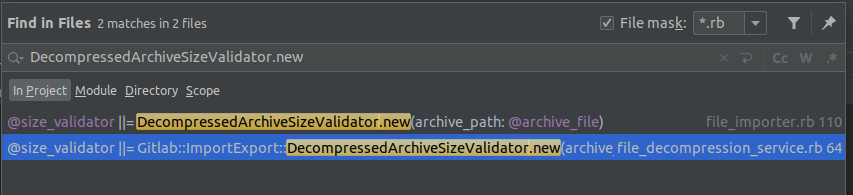
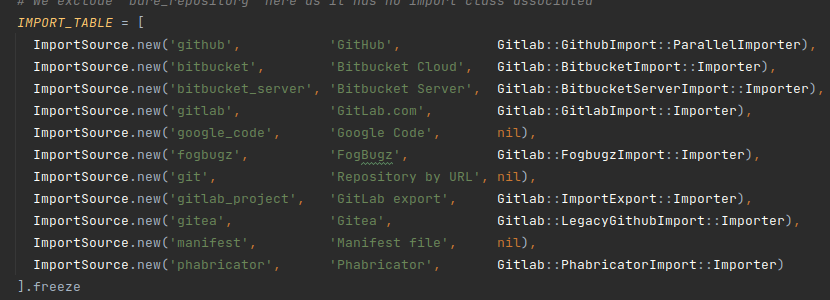
class DecompressedArchiveSizeValidator is used in 2 places which are:
- file_importer.rb
- file_decompression_service.rb
Side note about workers in GitLab
Gitlab works on the mechanism that the web interface only performs processing of general tasks. For heavier tasks, it uses sidekiq as workers, performing jobs, which are pushed from the web controller.
This is also the reason why when setting up the debug environment, you will have to add a debug config for sidekiq.
Case 1:
First, we will take a look at the file_importer.rb branch, We start from Import::GitlabProjectsController and it creates and calls Projects::GitlabProjectsImportService.new(current_user, project_params).execute to create the job.
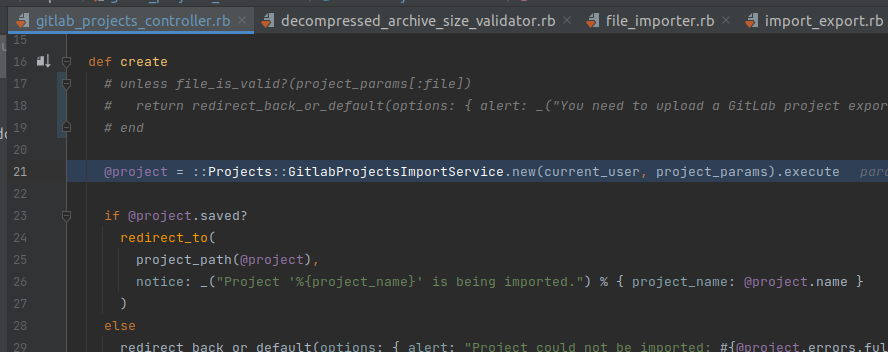
Lines 17, 18 and 19 have been commented to make debugging easier. I don’t understand why the debug environment with GDK is faulty. All uploaded files are reported invalid!! This problem doesn’t occur in product versions.
project_params, which used to create the project, has been limited, only allowing parameters to be passed: name, path, namespace_id, file
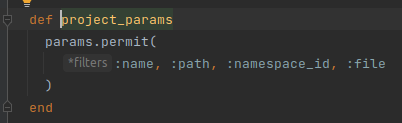
The stacktrace to this place:

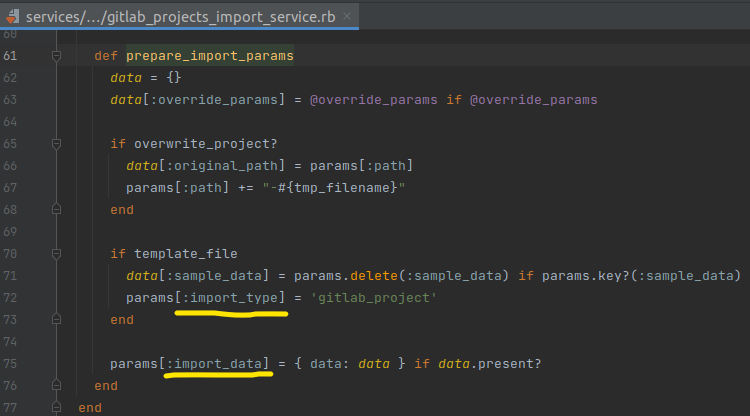
From GitlabProjectsImportService.execute continue to call prepare_import_params to edit, add and remove other important parameters (1)
Then, GitlabProjectsImportService.execute calls Projects::CreateService.execute again to create a Project with the params passed from GitlabProjectsController. At Projects::CreateService.execute, if the project being imported is not a template, the method will continue to initialize the Project object with the passed params:
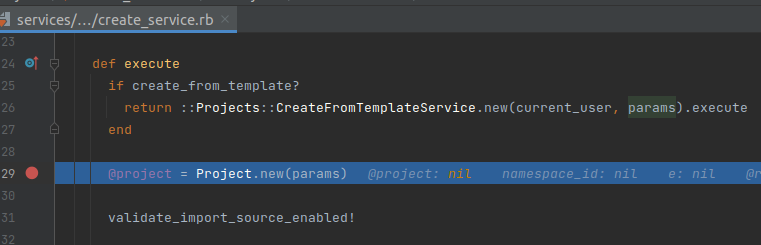
Once the project is created, the method will continue to go into the branch calling validate_import_source_enabled! to validate the import_type:
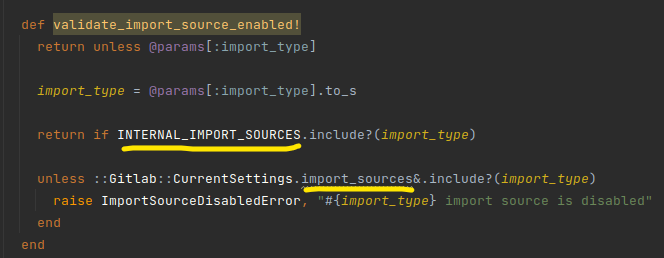
There will be two branches that will satisfy the condition, with the first condition, import_type belonging to one of the following types.
INTERNAL_IMPORT_SOURCES = %w[bare_repository gitlab_custom_project_template gitlab_project_migration].freeze
In the second case, import_type would have to exist in the list Gitlab::CurrentSettings.import_sources:
After creating the Project object and doing some more miscellaneous modifications, this method will call Projects::CreateService.import_schedule to add a schedule for the worker to do the import:
def import_schedule
if @project.errors.empty?
@project.import_state.schedule if @project.import? && !@project.bare_repository_import? && !@project.gitlab_project_migration?
else
fail(error: @project.errors.full_messages.join(', '))
end
end
To be added into the import schedule, this project must have an import type of gitlab_project.
Once added to the schedule, the worker will receive the job and execute the following:
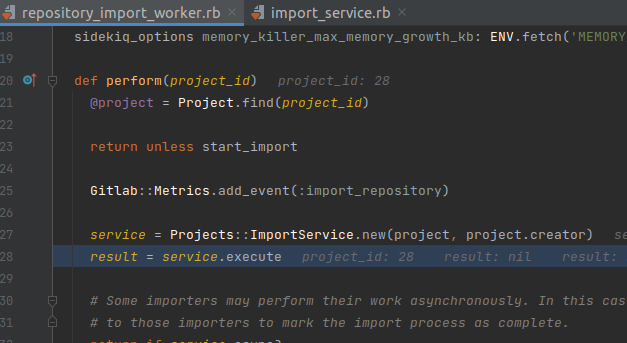
Stacktrace to DecompressedArchiveSizeValidator.execute
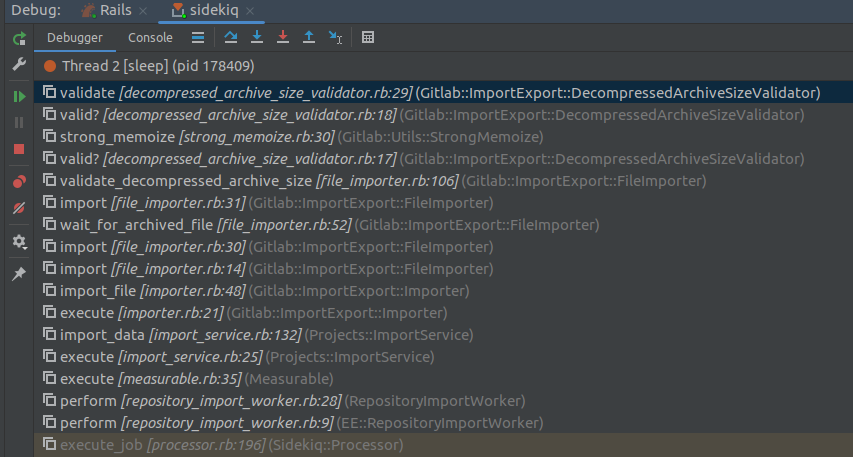
However, according to this branch, we cannot control @archive_path
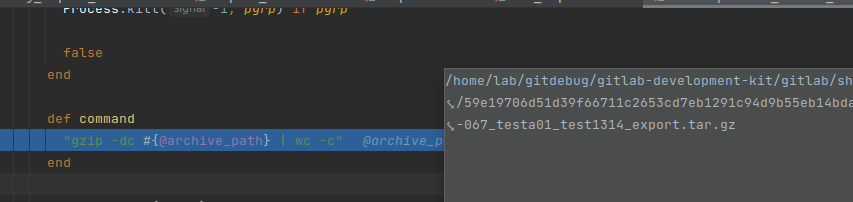
When the worker executes a job, @archive_file is taken from Project.import_source. However, this attribute is not set by default and has null value!
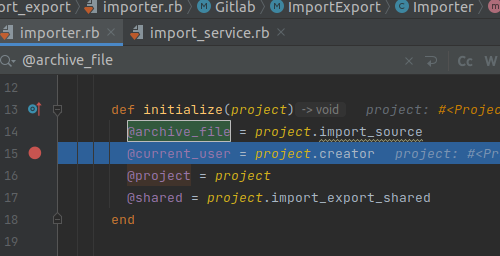
This value remains null at Gitlab::ImportExport::FileImporter.new
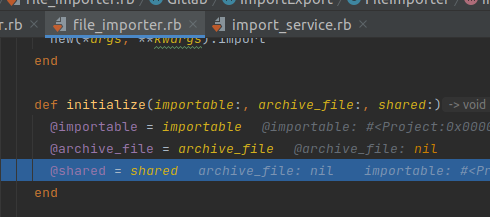
Only when calling Gitlab::ImportExport::FileImporter.copy_archive, would this value be set:
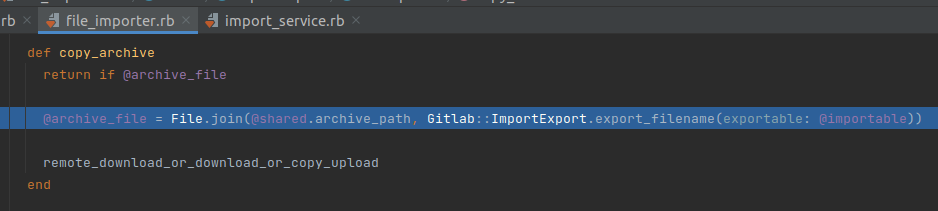
@archive_file_name is generated based on the full_path of the Project, so this value cannot be manipulated. According to this branch, we cannot have bug command injection ¯_(ツ)_/¯

Case 2
The file_importer.rb branch was confirmed as not exploitable, so I switched to the second branch to analyse. The second branch is file_decompression_service.rb
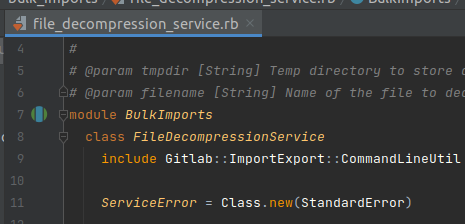
This branch is quite difficult to analyze and needs more findings to get the right payload to access.
First, you must go to the import group feature of GitLab and fill in information like GitLab URL and access token.
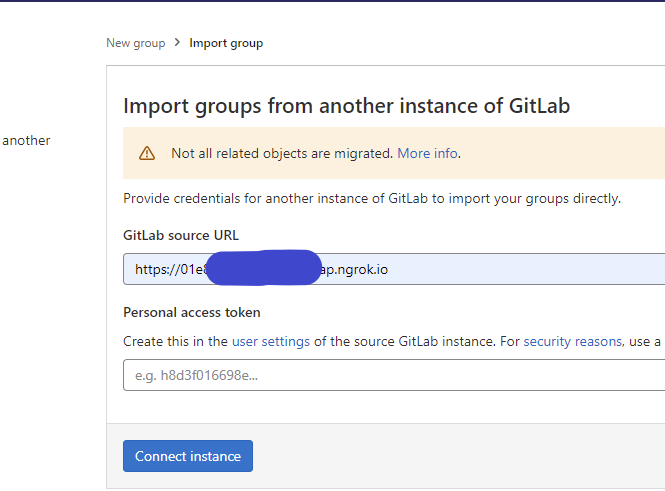
After filling it correctly, we will get to the import page. Just click on Import button to start importing:
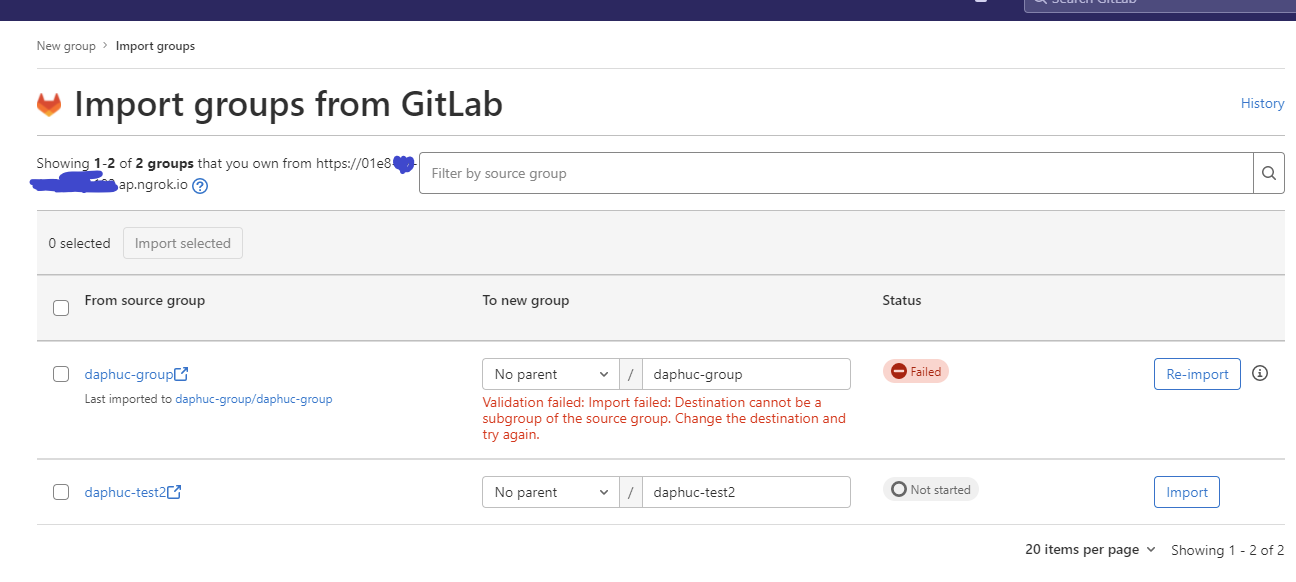
Back to Burpsuite requests history, we have a request like this:
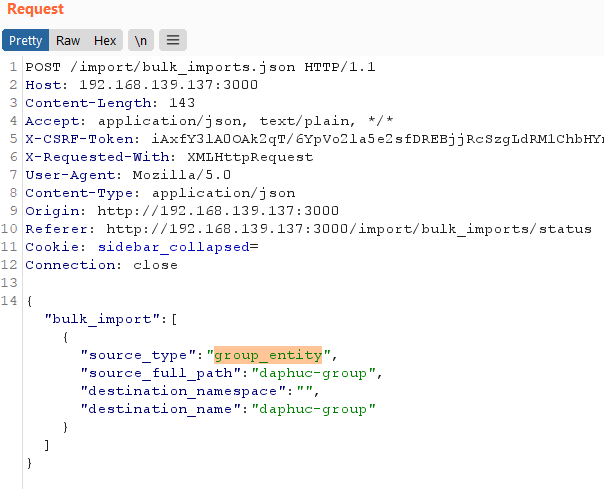
Searching for the group_entity keyword in the source code, I discovered that in addition to group_entity, there is also project_entity:
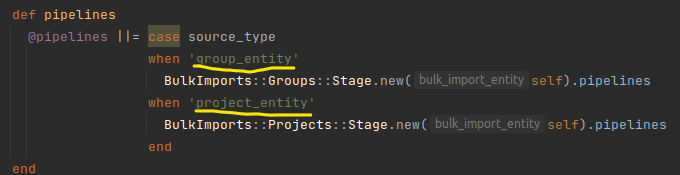
I can’t find this feature on the web or in any document. Most likely, this is a hidden, developing feature of GitLab!
This Bulk Import feature is handled by Import::BulkImportsController.
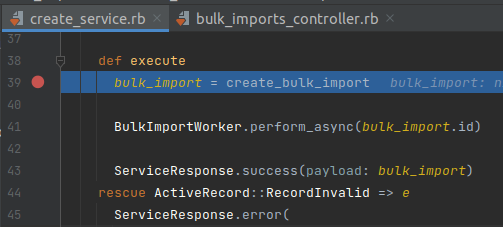
After executing create_bulk_import, the BulkImportsController.execute method continues to call BulkImportWorker.perform_async, the method content is as follows:
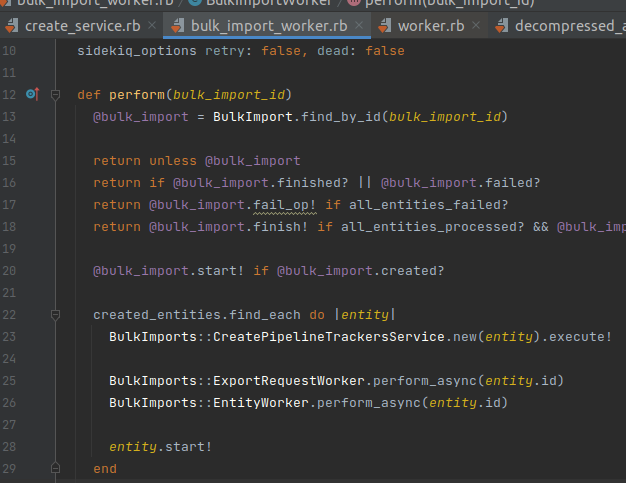
Notice the call to BulkImports::CreatePipelineTrackersService.new(entity.execute!). This method considers which Pipelines are suitable to execute with the passed parameters:
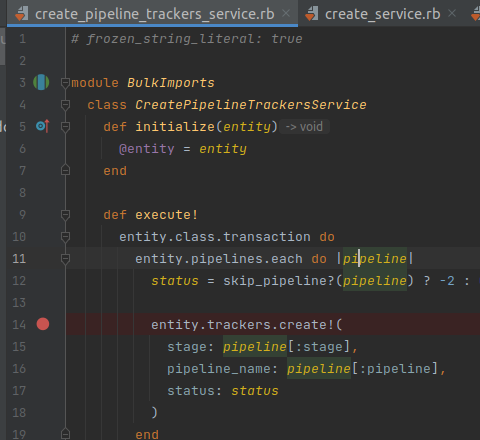
For example, with project_entity, we have some Pipelines like this:
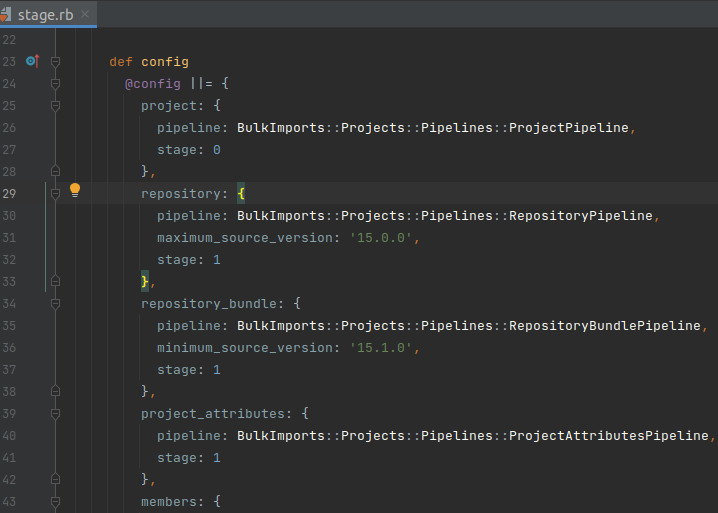
Site notes about Pipeline in Bulk Import
This concept is exclusive to Bulk Import. The executable file for these Pipelines is lib/bulk_imports/pipeline/runner.rb.
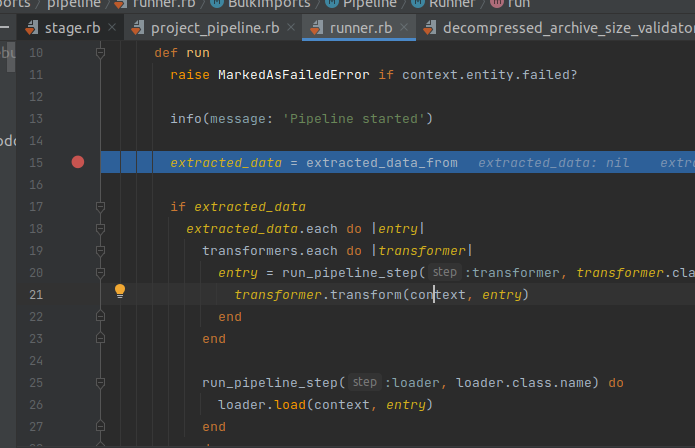
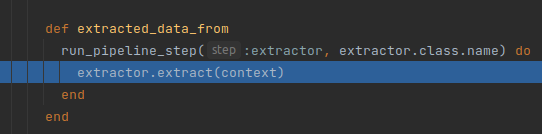
Pipelines will have declarations and override methods such as extract, transform, load and after_run.
The runner will browse and execute these methods in order: extract data, transform data, load data, after_run
And will execute the Pipelines in turn in the order declared in the stage.rb file.
Going back to the Bulk Import project, the ProjectPipeline pipeline will be the first pipeline to be executed.
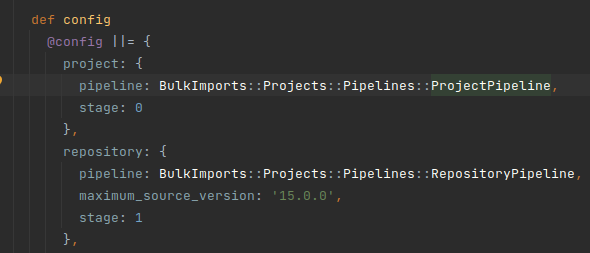
Contents of ProjectPipeline:
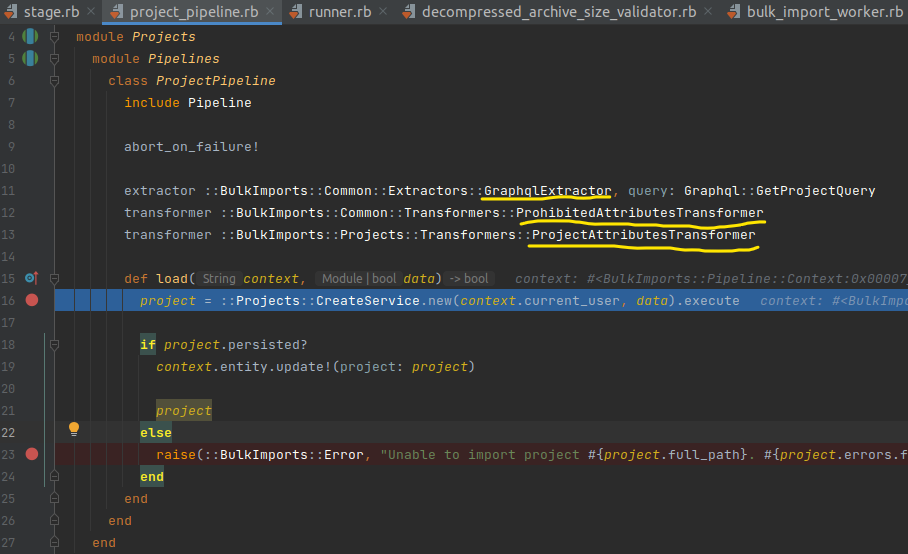
In the ProjectPipeline.load, there’s a call to Projects::CreateService.execute with the parameter params = data. As mentioned in the side note, data is the data modified by Transformers.

ProjectPipeline’s extractors and transformers are:
extractor ::BulkImports::Common::Extractors::GraphqlExtractor, query: Graphql::GetProjectQuery
transformer ::BulkImports::Common::Transformers::ProhibitedAttributesTransformer
transformer ::BulkImports::Projects::Transformers::ProjectAttributesTransformer
According to Pipeline’s flow:
GraphqlExtractor.extractwill get data from the target through graphqlProhibitedAttributesTransformer&ProjectAttributesTransformerwill modify the received data
With GraphqlExtractor, in GitLab’s fix commit Graphql::GetProjectQuery is fixed as follows:
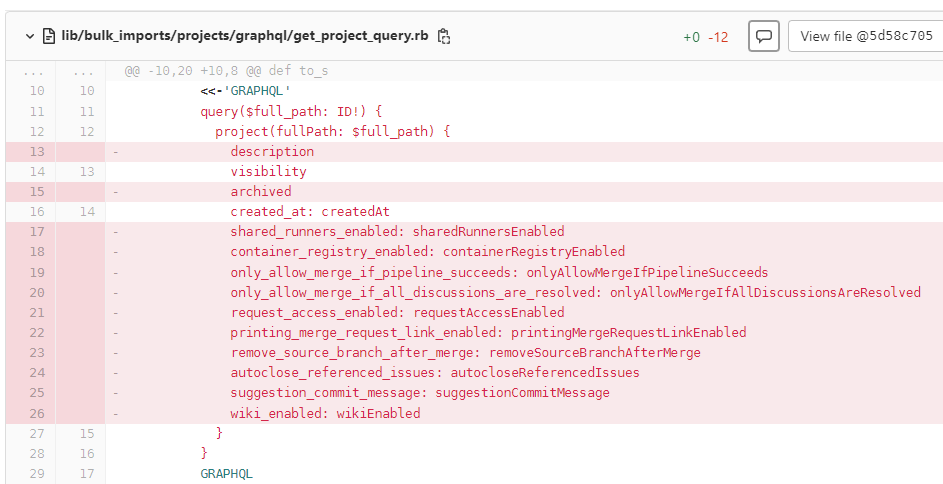
It can be clearly seen here that variables to be retrieved has been mostly reduced.
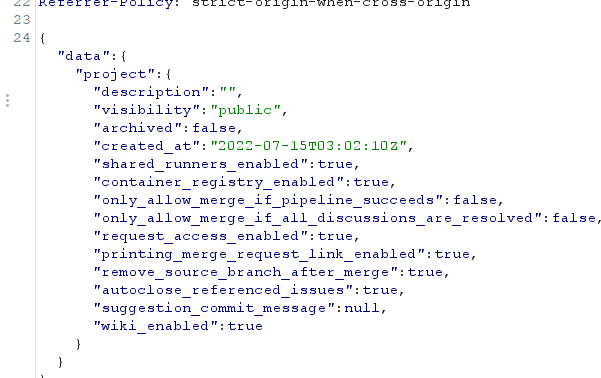
Here is an example of data retrieved from GraphqlExtractor:
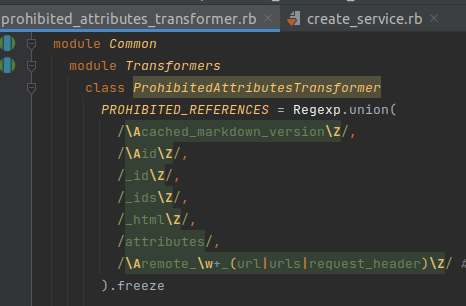
With ProhibitedAttributesTransformer, the main function of this transformer is to remove some sensitive attributes:
With ProjectAttributesTransformer.execute:
This method takes data, does a few extra steps to set the necessary attributes like import_type, name, path and then calls data.transform_keys!(&:to_sym) to perform the conversion. All the keys of the Hash just passed into the Symbol form.
// In Ruby there is a Symbol vs String concept. Roughly Symbol will have a colon “:” in front
Here is an example after doing data.transform_keys!(&:to_sym)
- And remember,
datais still completely controllable because it’s retrieved from GraphQL, GraphQL and is taken from our website.
Going back to the import mentioned in Case 1, we can completely record project.import_source, from which we can control @archive_file and RCE (〜 ̄▽ ̄)〜
In the fix commit of ProjectAttributesTransformer, instead of accepting retrieved data, this transformer created a new Hash, and only adds some necessary keys/values and return the clean Hash, meaning that other attributes were not added:
Currently, data after being extracted and transformed will be passed into Projects::CreateService.execute
Unfortunately, projects created from ProjectPipeline can only have import_type = gitlab_project_migration
However, at the import_schedule, this project will be rejected by condition [email protected]_project_migration?
def import_schedule
if @project.errors.empty?
@project.import_state.schedule if @project.import? && !@project.bare_repository_import? && !@project.gitlab_project_migration?
else
fail(error: @project.errors.full_messages.join(', '))
end
end
Although it is possible to control the attributes of the Project object, the most important attribute has been overwritten and there is no way to override it (actually yes, but I will talk about it in another post).
Case 1 + 2 = 3
And… I was stuck there for almost 2 weeks figuring out the debugging feature of ruby. Sometimes it touches the breakpoint, and sometimes it doesn’t. Sometimes RubyMine suddenly crashes, which is causing quite a headache for me.
Until the last few days, I found another way to debug faster without turning on the GitLab server, which is to use GitLab’s RSpec to debug. The convenience of this method is to avoid waiting for the sidekiq worker.
From there, I started to debug ProjectPipeline with project_pipeline_spec.rb, modify some data related to project_data and then run it:
Thanks to that, my debugging is really fast and I have achieved some new results.
After carefully re-reading the Projects::CreateService.execute branch, I realized that I missed the template processing branch:
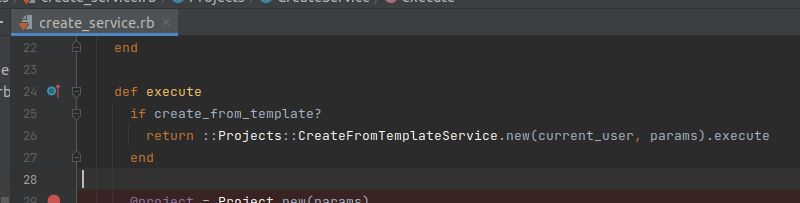
This branch calls Projects::CreateFromTemplateService.execute with params, which is data taken from ProjectPipeline.
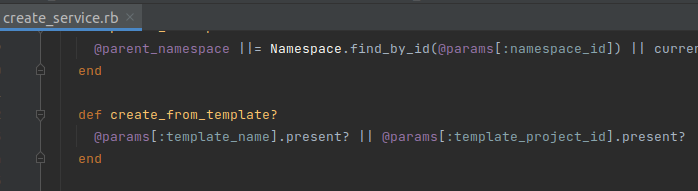
This method mainly checks the existence of template_name, then calls GitlabProjectsImportService.execute along with params for further processing:
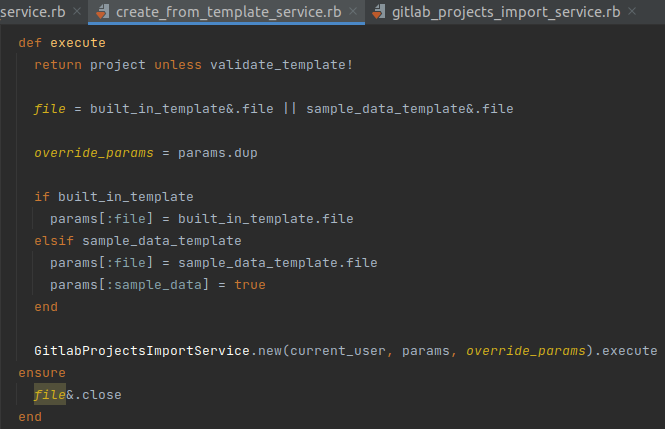
As discussed in part 1, GitlabProjectsImportService.execute will then call prepare_import_params to process the params:
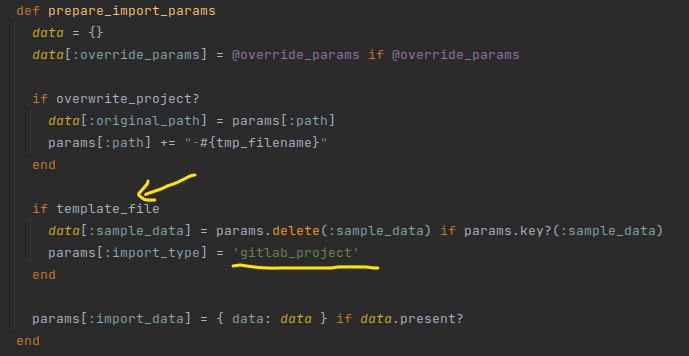
Here, if the template_file exists, the program will overwrite param import_type to gitlab_project.
After processing the param, GitlabProjectsImportService.execute will call Projects::CreateService.execute to re-create the project with the modified params.
So, the import_type has been changed to gitlab_project, which still reuses old Pipeline params => RCE ( ͡° ͜ʖ ͡°)( ͡° ͜ʖ ͡°)( ͡° ͜ʖ ͡°)
There was a note that the injected command will not be executed immediately!
At Gitlab::ImportExport::FileImporter.import, the wait_for_archived_file method will be called to wait for @archive_file existence before entering the lower processing branch (the branch that we inject command)
Contents of wait_for_archived_file method:
With MAX_RETRIES = 8, this program will loop 8 times to wait for the file’s existence, with each time it will sleep 2^i, I apply the formula to calculate the sum of the power series. This can be verified by the first year students and we know that we will have to wait 2^8 -1 = 255 seconds if the file doesn’t exist:
And in case the file does not exist, this method also continues to call yield at the bottom, which means that the statements after wait_for_archived_file are still called normally, for example:
At this point, everything about this bug is clear, although the process of reading Ruby/Rails is quite painful, but it also brings a lot of knowledge and some interesting things.
Proof of Concept video:
It’s Demo Time!
If the video failed to load, here is the backup
Thanks for reading!